摘要:論文《基于RF-Light GBM的分組密碼算法識別方案》發表在《北京電子科技學院學報》,本文僅共展示,來自網絡平臺。 摘要密碼算法的識別在密碼分析領域中具有重要意義。目前主流分組密碼算
論文《基于RF-Light GBM的分組密碼算法識別方案》發表在《北京電子科技學院學報》,本文僅共展示,來自網絡平臺。
摘要密碼算法的識別在密碼分析領域中具有重要意義。目前主流分組密碼算法識別方案中,密文特征提取普遍基于隨機性檢測標準。為解決短樣本識別需求以及進一步提高識別準確率,本研究提出了一種基于RF-LightGBM的分組密碼體制識別方案。首先通過GM/T0005-2021隨機性檢測標準提取密文特征,其次利用隨機森林算法對高維的數據進行重要性排序和篩選,然后利用特征向量訓練LightGBM算法模型構建密碼算法識別分類器進行識別。實現了短樣本環境下高效識別未知密文的識別需求。在兩兩識別實驗中,與現有研究相比本方案準確率整體提升約12%;多分類實驗顯示準確率均在73%以上,驗證了本方案在分組密碼算法識別中的有效性和優勢,為未來在更復雜的加密模式下進行密碼算法識別提供了參考。
關鍵詞:分組密碼;機器學習;隨機性檢測;密碼算法識別;LightGBM
0 引言
隨著信息安全需求的不斷增長,密碼學在保護數據機密性和完整性方面發揮著至關重要的作用。作為對稱加密算法的基礎之一,分組密碼算法被廣泛應用于各種加密系統中,如數據存儲、網絡通信和金融交易等領域。分組密碼算法的核心目標是通過對固定長度數據塊的加密,實現數據的保密性。然而,隨著密碼學研究的深入,密文分析技術的不斷發展,密碼算法的識別問題逐漸成為學術界和工業界的研究熱點[1]。通過分析密文的特征信息,識別出加密所使用的算法,可以有效地評估密碼系統的安全性,并對潛在的攻擊風險進行預測[2]。
分組密碼算法的識別主要是通過分析加密后的密文,推測出其所采用的具體加密算法[3]。隨著加密算法的不斷進化,密文的特征往往變得更加復雜和難以直接辨識。近年來,機器學習方法被逐漸引入到密碼算法識別領域,尤其是集成學習和深度學習方法的應用,顯著提升了識別的準確性和效率。具體來說,基于機器學習的密碼算法識別系統首先通過從密文中提取特征,構建特征向量,然后利用分類算法進行訓練和識別。
目前,主流分組密碼識別方案中的密文特征提取主要基于隨機性檢測標準,其中,主要為NIST SP800-22隨機性檢測標準[4]和GM/T0005-2021隨機性檢測規范[5]。GM/T0005-2021隨機性檢測規范是國家密碼管理局于2021年發布的一項重要標準,是在GM/T0005-2012隨機性檢測規范的基礎上進行了修訂和擴展,適用范圍從原先的“適用于對隨機數發生器產生的二元序列的隨機性檢測”擴展為“適用于對二元序列的隨機性檢測”,進一步提升了其普適性和實用性。由此本文選擇GM/T0005-2021標準的15種檢測方法作為提取特征向量方法。
如今,機器學習方法逐漸在密碼識別領域中被廣泛應用[6],此方法有著堅實的理論基礎和豐富的實踐經驗,并且在設計過程中表現出相對的簡單性和穩定性,能夠有效處理數據之間復雜的關系。這使得基于機器學習的密碼識別方案在效率和準確性上均取得了顯著的優勢。所以本文結合了機器學習算法和GM/T0005-2021標準提出了基于RF-LightGBM的分組密碼算法識別方案,旨在進一步探索短樣本環境下對未知密文進行高效快速識別,為密碼算法設計和安全性評估提供一定的參考。
基金項目:中央高校基本科研業務費專項資金資助項目(3282024046)。
作者簡介:董秀則(1976-),男,山東莒縣人,副教授,研究方向為信息安全與密碼工程;楊鴻剛(1999-),男,河北滄州人,碩士研究生,研究方向為網絡空間安全;胡一凡(2001-),男,安徽合肥人,碩士研究生,研究方向通信工程;于庚辰(2000-),男,山東臨沂人,碩士研究生,主要研究方向網絡空間安全。
1 相關工作
2018年,黃良韜等人[7]對已有密碼算法分類研究進行了總結,并提出了一個密碼算法識別系統,該系統利用隨機森林算法對古典密碼、流密碼、分組密碼和公鑰密碼進行了層次化識別。2019年,趙志誠等人[8]綜合使用隨機性測試、比特熵和不定長文本向量等方法,設計了密文特征,并對Grain-128密碼算法與其他11種對稱密碼算法進行了逐對區分。同年,趙志誠等人[9]基于NIST隨機性測試標準,提出了一個基于隨機森林的密碼體制識別方案,該方案能有效區分明密文及不同模式的分組密碼密文,還能準確識別AES、DES、3DES等六種密碼體制。
2021年,紀文桃等人[10]和曹莉茹[11]分別實現了對商密SM4算法與其他分組密碼算法的逐對識別以及對八種密碼算法進行了分類。二者方案都通過隨機性測試選擇密文特征,后者通過BP神經網絡、卷積神經網絡和循環神經網絡等深度學習方法。
2022年,劉節威等人[12]實現了對商密SM4算法與其他算法的識別。通過對商用分組密碼算法進行識別研究,提出了一種結合自動編碼器和卷積神經網絡的識別方案。同年,夏銳琪等人[13]提出了一種基于機器學習和特征工程的加密模式識別方法,采用5種加密方式進行識別。
2023年,袁科等人[14]以分組密碼算法為研究對象,提出一種混合隨機森林和邏輯回歸模型的分組密碼算法辨識方案,基于NIST隨機性特征提取方法,選取AES、3DES、Blowfish、CAST和RC2五個分組密碼作為研究對象,開展密文分類任務。同年,夏銳琪等人[15]將游程分布指標、特征分布函數和KL散度等概念融入研究中,探究Feistel和SPN結構的不同,構建了機器學習模型,對十二種分組密碼算法進行識別。
2024年,張運理等人[16]采用隨機數檢測規范中的檢測項對密文進行檢測得到P_Value和Q_Value,并將其作為密文特征項,基于集成學習模型構建了識別模型,實現了唯密文場景下的分組密碼算法識別技術。
2 基本理論
2.1 機器學習識別原理
在探討密碼算法的多樣性時,必須認識到不同算法在核心設計理念、組件架構、操作機制以及密鑰管理方式上的本質區別。這種差異,加之明文數據類型的多樣性,可能會影響加密后密文的空間分布特征[17]。因此,對于密文識別的核心在于精確捕捉這些密文數據之間的細微差異,以實現密碼算法類型的精準區分[18]。
目前,密碼算法識別的研究主要采用分類思想,構建的完整識別系統分為兩個主要部分。首先,對密文文件進行提取密文特征,然后匯總生成特征向量。其次,選擇分類算法,輸入特征向量進行訓練,以完成分類任務。文獻[9]給出了完整的密碼體制識別方案的定義是(Gamma=(M, J, h^{J}))。
密碼算法集合(M={m_1, m_2, cdots, m_n}),其中n為密碼算法的個數。J代表當前密碼體制識別的策略,(h^{J})是密文識別結果的評價指標,指的是在當前密碼識別條件下,識別方案可正確識別密碼體制的概率或準確率。在公式(Gamma=(M, J, h^{J}))中,核心部分是密碼體制識別方案J,一般的J表示為三元組結構如式(J=(oper, fea, CA))。
三元組中的oper代表識別方案的具體工作流程,fea為從密文中提取出的特征,CA是識別過程中具體用到的識別算法。
2.2 梯度提升的基本原理
梯度提升(Gradient Boosting)的基本原理是通過構建一系列的弱學習器(通常是決策樹),每個新的學習器都試圖修正前一個學習器的錯誤,從而逐步提高整體模型的性能[19]。
梯度提升模型表示為:
[F(x)=sum_{m=1}^{K} �eta_{m} h_{m}(x)]
其中,(h_m(x))是第m棵決策樹,(�eta_m)是其對應的權重。
初始化模型:
[F_{0}(x)=arg min _{�eta} sum_{i=1}^{N} Lleft(y_{i}, �eta
ight)]
其中,(L(x, y))為損失函數,意為找出一個變量(或一組變量),使得一個給定函數在這些變量取值時達到最小值;(�eta)是第i個樣本通過當前決策樹模型的預測值,(y_i)是第i個樣本的真實值。
計算當前模型的殘差:
[r_{i, m}=-left[frac{partial Lleft(y_{i}, Fleft(x_{i}
ight)
ight)}{partial Fleft(x_{i}
ight)}
ight]_{F(x)=F_{m-1}(x)}]
擬合一棵新樹(h_m(x))來預測殘差。
更新模型:
[F_{m}(x)=F_{m-1}(x)+�eta_{m} h_{m}(x)]
其中,(�eta_m)是步長(學習率)。
2.3 P_value值
P_value值[11]是指在期望(理論)分布中觀察到的統計量與在具體實驗中所得到的統計量相同或更大的概率。在假設檢驗的框架內,它反映了在零假設為真的條件下,獲得當前或更極端結果的可能性。當計算出的P_value值高于預設的顯著性水平(alpha)時,我們認為零假設是可以接受的;反之,則應拒絕零假設。對于隨機數序列檢測,P_value表明序列是否偏離了隨機性假設。
Q_value值是一種校正后的顯著性概率,用來衡量在多重假設檢驗中,將某一個假設判為顯著(拒絕零假設)時,錯誤拒絕的概率(即假陽性概率)。
3 密碼算法識別方案
3.1 方案總體框架
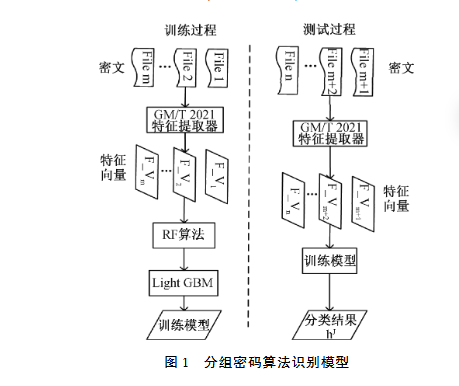
如圖1所示,本識別方案包含訓練階段和測試階段。先使用研究的密碼算法對其明文進行加密得到對應的密文。在訓練階段,首先收集P種密碼算法加密的組密文文件,每組包含n個文件,為了劃分數據集,將每組n個文件劃分10等份,其中每一份都作為一次驗證的測試集,其余九份作為訓練集。具體來說,整個過程將進行10次,每次選擇不同的一份作為測試集,其余九份作為訓練集,通過這種交叉驗證的方法,可以全面利用每個密文數據。然后,通過GM/T0005-2021特征提取器對抽取的密文數據進行特征提取,密文輸入進提取器會生成對應的P_value值作為特征向量,構成特征矩陣,每一行代表一個密文文件,每列代表一個提取的特征。再對每個特征向量標記與其密碼體制類別相對應的標簽,這些特征向量被整合在一起組成訓練集。然后,采用隨機森林算法對每個特征進行重要性評估,通過計算特征在決策樹中的貢獻度,能夠判斷出哪些特征對加密算法的識別最有幫助。基于這些評估結果,篩選出最具區分性的特征集。這些選定的特征集被輸入到LightGBM分類器中,進行模型訓練。LightGBM使用梯度提升決策樹(GBDT)方法,高效地處理大規模數據,生成準確性和魯棒性較高的分類模型。
在測試階段,將剩余的特征向量作為測試集輸入到已經訓練好的LightGBM分類器中,進行分類測試,最終輸出每個密文的加密算法類別,并通過準確率、召回率和F1值等指標評估分類效果。通過這一步驟,實現了對分組密碼算法的識別,確保了本方案在識別不同密碼算法加密的密文時具有高度的準確性和可靠性。
(圖1 分組密碼算法識別模型)
3.2 隨機森林
隨機森林是一種強大的集成學習方法,通過構建多個在不同數據子集上訓練的決策樹并結合它們的預測結果來提高模型性能和穩定性[20]。它利用隨機抽樣和隨機特征選擇來增加模型多樣性、降低過擬合風險,并通過投票機制或平均值集成決策樹的預測結果,適用于分類和回歸任務,通常具有較高準確性。
本文結合過濾式和包裹式方法來篩選特征集,其中過濾式方法使用特征選擇算法進行篩選,包裹式方法則通過評估模型性能變化來選擇最佳特征集。隨機森林算法在很大程度上克服了模型過擬合的問題,具有良好的泛化性能和較高的預測精度[21]。此外,它能夠有效處理高維特征的數據,評估各個特征的重要性,并按重要性進行排序。
3.3 LightGBM分類器
LightGBM作為實現GBDT(Gradient Boosting Decision Tree)算法框架之一,支持高效率的并行訓練,并且具有更快的訓練速度、更低的內存消耗、更好的準確率,以及支持分布式可以快速處理海量數據等優點[22]。LightGBM在傳統的GBDT算法上進行了直方圖算法、GOSS、EFB、Leaf-wise樹生長策略以及支持類別特征等優化措施[23]。由此本文將LightGBM模型引入到分組密碼識別方案中,探討研究利用未知密文識別分組密碼加密結構的問題。
LightGBM使用直方圖算法(Histogram)對特征值進行離散化,減少了特征分裂點的計算量[24]。傳統的GBDT需要遍歷所有特征值來找到最佳分裂點,而直方圖算法通過將特征值劃分為固定數量的區間(bins),如在本方案中特征向量為0到1的浮點數,可以將其劃分為5個區間,然后在直方圖上找到最優的分裂點,通過計算每個區間的分裂增益,選擇增益最大的區間進行分裂。通過減少計算分裂點的次數,顯著降低了計算復雜度。
對于分割點的增益Gain可定義為式(5):
[Gain =sum_{i=1}^{left} w_{i}+sum_{j=1}^{right} w_{j}-sum_{k=1}^{all} w_{k}]
其中,(sum_{i=1}^{left} w_{i})和(sum_{j=1}^{right} w_{j})分別代表左右子節點梯度統計量,(sum_{k=1}^{all} w_{k})代表初始節點的梯度統計量總和。
如圖2所示,在Histogram算法之上,LightGBM進行進一步的優化,使用了帶有深度限制的按葉子生長(leaf-wise)算法。該算法每次選擇當前所有葉子節點中分裂增益最大的葉子進行分裂,能生成更深的樹結構。這種策略可以更好地處理不平衡的數據分布,提高模型的精度[25]。在本分組密碼算法識別方案中,Leaf-wise的生長方式使得每次分裂都能最大化信息增益,從而提升模型的學習能力和預測準確性,適用于本方案特征向量為浮點數這種高精度預測的場景。其中,選擇信息增益最大的分裂,這個過程可以表示為式(6):
[Gain =frac{1}{2}left[frac{G_{L}^{2}}{H_{L}+lambda}+frac{G_{R}^{2}}{H_{R}+lambda}-frac{left(G_{L}+G_{R}
ight)^{2}}{H_{L}+H_{R}+lambda}
ight]-gamma]
其中,(G_L)和(G_R)分別代表左子結點和右子節點的梯度和,(H_L)和(H_R)分別代表左子節點和右子節點的二階導數和,(lambda)為正則化參數,(gamma)為葉子節點分裂的最小增益閾值。
LightGBM模型算法流程如圖3所示,首先進行數據預處理,將連續特征離散化為k個桶,處理缺失值,將缺失值單獨作為一個類別。然后進行初始化模型(F_0(x))。在迭代訓練階段,對每次迭代m:計算當前模型的殘差;構建直方圖,加速尋找最佳分割點;使用基于葉子的生長策略,選擇當前損失最大的葉子節點進行分裂;最后更新模型(F_m(x))。訓練完成后輸出最終的預測模型(F_M(x))。
(圖2 Leaf-wise樹生長)
(圖3 LightGBM模型算法流程)
4 實驗設置及結果分析
4.1 數據集與參數設置
本文使用的明文數據來自AG News(AG's News Corpus),將其隨機切割出2000個32KB的文檔,以二進制方式讀取。為了加密這些文檔,使用Crypto庫對五種分組密碼算法(DES、AES、3DES、Blowfish、RC2)進行了實現,通過OpenSSL庫對IDEA、CAST、SM4這三種分組密碼進行了實現。在所有的加密過程中,均為ECB工作模式,以確保加密的一致性,如表1所示。對同一密碼算法在模型訓練和測試的過程中,采用統一的密鑰。為了提取這些密文文件的特性,編寫了符合《GM/T0005-2021隨機性檢測規范》的Python代碼作為特征提取器,對密文進行了特征提取,然后將這些特征向量進行匯總并打上算法對應標簽構建了本文的數據集。
表1 分組密碼算法參數表
| 密碼算法 | 密鑰長度/bit | 算法結構 | 加密模式 | 實現方式 |
| ---- | ---- | ---- | ---- | ---- |
| DES | 56 | Feistel | ECB | Crypto |
| AES | 128 | SPN | ECB | Crypto |
| 3DES | 168 | Feistel | ECB | Crypto |
| Blowfish | 128 | Feistel | ECB | Crypto |
| RC2 | 128 | Feistel | ECB | Crypto |
| IDEA | 128 | SPN | ECB | OpenSSL |
| CAST | 128 | Feistel | ECB | OpenSSL |
| SM4 | 128 | Feistel | ECB | OpenSSL |
本方案通過編寫GM/T0005-2021標準的Python代碼實現特征提取器來對密文進行特征提取,該特征提取器包含十五個檢測項,通過檢測項計算得到p_value值。為了增加特征向量的維度,本文對原有十五種檢測項中的部分檢測項進行了參數設置[9],如其中游程分布檢測設置針對長度為2到10的游程進行檢測,則該檢測返回9個值;撲克檢測中設置(m=2,4,8),則該檢測返回3個值;設定二元推導檢測中參數(k=7),每進行一次推導返回一個對應的值,即進行7次推導后,返回7個值;設置自相關檢測的參數d分別等于1,2,4,8,10,16,即可返回6個p值;近似熵檢測的參數為(m=2)和(m=5),則此檢測可以返回兩個值。由此共可獲得42維特征向量,具體參數設置和檢測項簡介如表2所示。
表2 隨機性檢測方法參數表
| 檢測項 | 檢測參數 | 返回值數 |
| ---- | ---- | ---- |
| 單比特頻數檢測 | - | 1 |
| 塊內頻數檢測 | (m=1000,2000,3000,5000) | 4 |
| 撲克檢測 | (m=2,4,8) | 3 |
| 重疊子序列檢測 | (m=3,5) | 1 |
| 游程總數檢測 | - | 1 |
| 游程分布檢測 | 長度2-10 | 9 |
| 塊內最大游程檢測 | (m=500,5000) | 2 |
| 二元推導檢測 | (k=7) | 7 |
| 自相關檢測 | (d=1,2,4,8,10,16) | 6 |
| 矩陣秩檢測 | - | 1 |
| 累加和檢測 | - | 2 |
| 近似熵檢測 | (m=2,5) | 2 |
| 線性復雜度檢測 | (m=500,1000) | 1 |
| Maurer 通用統計檢測 | (L=7,Q=1280) | 1 |
| 離散傅立葉檢測 | - | 1 |
4.2 評估標準
在分類問題評價標準中,最常用的標準為準確率、精確率、召回率、F1分數[26]。
(1)準確率(Accuracy):準確率是模型預測正確的樣本數占總樣本數的比例。
[Accuracy =frac{TP+TN}{TP+TN+FP+FN}]
(2)精確率(Precision):是指所有被預測為正類的樣本中實際為正類的比例。
[Precision =frac{TP}{TP+FP}]
(3)召回率(Recall):是指所有實際為正類的樣本中被正確預測為正類的比例。
[Recall =frac{TP}{TP+FN}]
(4)F1分數:是精確率和召回率的調和平均數,是權衡精確率和召回率的一個綜合指標。
[F_{1}=frac{2TP}{2TP+FP+FN}]
在本研究中以準確率和F1分數為主要評估標準。
4.3 特征分布
本文分別對DES、AES、3DES、Blowfish、IDEA、CAST、SM4、RC2的密文文件進行隨機性測試分析,得到這些分組算法密文文件的P_value值。本研究選取塊內頻數檢測在分塊為2000bit下繪制特征分布圖,橫坐標為P_value值,縱坐標為文本數量,如圖4所示。在塊內頻數檢測的條件下差異化明顯,Blowfish和IDEA算法的文本數量隨著P_value值的增加而減少,DES、SM4、RC2、CAST算法的文本數量隨著P_value值的增加而增加,尤其是DES算法在P_value值為0.9~1.0范圍內增加顯著。
(圖4 特征分布圖)
4.4 分類識別結果與分析
在本研究分類識別部分中,首先進行了DES、AES、3DES、Blowfish、IDEA、CAST、SM4、RC2八種分組密碼算法的兩兩識別,每個密碼算法的密文為2000個,且均在ECB模式下加密生成,每個密文大小為32KB。為充分利用數據并且減少過擬合,本方案使用十折交叉驗證進行分類實驗。
如表3所示,本方案兩兩識別準確率和F1分數均取得了不錯的效果,僅有4組兩兩識別結果為80%以上,其余均在90%以上。其中十一組兩兩識別對比實驗準確率在98%以上,此外,F1分數也與準確率呈現相同的規律,說明模型穩定性良好。實驗結果如表4所示,所得實驗結果整體均高于四個對比文獻,相較參考文獻本方案得到的實驗結果整體準確率提升約12%。
表3 RF-LightGBM方案兩兩識別結果
| 算法 | 準確率/% | F1 分數/% | 算法 | 準確率/% | F1 分數/% |
| ---- | ---- | ---- | ---- | ---- | ---- |
| 3DES vs AES | 98.75 | 98.60 | Blowfish vs DES | 93.37 | 92.17 |
| 3DES vs Blowfish | 94.63 | 94.68 | Blowfish vs IDEA | 91.87 | 91.40 |
| 3DES vs CAST | 89.85 | 88.79 | Blowfish vs RC2 | 90.90 | 89.02 |
| 3DES vs DES | 90.13 | 89.80 | Blowfish vs SM4 | 98.25 | 98.13 |
| 3DES vs IDEA | 90.00 | 89.55 | CAST vs DES | 93.25 | 93.52 |
| 3DES vs RC2 | 87.50 | 86.62 | CAST vs IDEA | 92.25 | 91.80 |
| 3DES vs SM4 | 97.87 | 97.73 | CAST vs RC2 | 92.25 | 91.92 |
| AES vs Blowfish | 98.12 | 98.04 | CAST vs SM4 | 99.25 | 99.80 |
| AES vs CAST | 98.50 | 97.63 | DES vs IDEA | 93.64 | 92.08 |
| AES vs DES | 98.87 | 98.81 | DES vs RC2 | 89.87 | 89.26 |
| AES vs IDEA | 99.12 | 99.07 | DES vs SM4 | 98.37 | 98.13 |
| AES vs RC2 | 99.12 | 98.94 | IDEA vs RC2 | 90.25 | 90.87 |
| AES vs SM4 | 85.63 | 86.31 | IDEA vs SM4 | 98.37 | 98.56 |
| Blowfish vs CAST | 92.50 | 91.97 | RC2 vs SM4 | 98.62 | 98.55 |
表4 方案結果對比
| 識別方案 | 樣本長度 | 準確率范圍/% |
| ---- | ---- | ---- |
| 文獻[9] | 512kb | 45-89 |
| 文獻[12] | 512KB | 80-89 |
| 文獻[16] | 1-512KB | 80-84 |
| 文獻[13] | 1MB | 82-88 |
| 本文 | 32KB | 85-99 |
為了進一步驗證本文方案的識別效果,本研究繼續對多個分組密碼算法的多分類識別測試。在相同條件下分別采用RF-LightGBM模型和隨機森林模型進行實驗。在評估過程中,采用宏平均指標來計算F1值和準確率,以確保每個類別的性能都能得到公平且準確的評估。圖5給出了RF-LightGBM模型八分類情況下測試結果的混淆矩陣。
表5給出了RF-LightGBM模型和隨機森林模型多分類識別結果的對比。其中,RF-LightGBM模型的三分類識別準確率為91.01%,四分類準確率為89.67%,五分類準確率為84.37%,六分類準確率為81.85%,七分類準確率為77.08%,八分類準確率為73.60%。實驗結果表明,隨機森林模型方案的多分類實驗結果準確率和F1分數均低于RF-LightGBM模型方案。
(圖5 八分類混淆矩陣圖)
表5 多分類識別方案對比
| 分類 | RF-LightGBM準確率/% | RF-LightGBM F1度量/% | 隨機森林準確率/% | 隨機森林F1度量/% |
| ---- | ---- | ---- | ---- | ---- |
| 三分類 | 91.01 | 90.74 | 85.73 | 84.12 |
| 四分類 | 89.67 | 89.63 | 82.87 | 81.64 |
| 五分類 | 84.37 | 84.36 | 76.37 | 77.12 |
| 六分類 | 81.85 | 81.84 | 73.23 | 72.48 |
| 七分類 | 77.08 | 76.97 | 70.31 | 69.45 |
| 八分類 | 73.60 | 72.65 | 64.37 | 63.77 |
5 總結
為解決分組密碼識別的短樣本識別需求以及進一步提高識別準確率,本文提出一種基于RF-LightGBM的分組密碼體制識別方案,解決短樣本識別需求以及利用未知密文識別分組密碼加密結構的問題。使用DES、AES、3DES、Blowfish、IDEA、CAST、SM4、RC2八種分組密碼算法對每個大小為32KB的明文在ECB模式下進行加密得到密文。通過GM/T0005-2021特征提取器對其密文進行特征提取,將特征向量輸入隨機森林算法模型進行排序和篩選,將篩選后的特征向量輸入進LightGBM分類器進行兩兩識別測試。在八種分組密碼相互兩兩識別結果中,有四組密碼算法的識別準確率在80%~90%,其余二十四組密碼算法的識別率均在90%以上。相較于現有方案結果,本方案整體識別準確率約提高12%。其次,本文又對八種分組密碼進行了多分類實驗,并且在相同條件下對隨機森林模型進行測試,本方案所得實驗結果均高于對比模型。其中,本方案八分類的識別準確率為73.60%。以上實驗結果驗證了GM/T0005-2021標準作為提取較短樣本長度特征向量的可行性,以及RF-LightGBM方案識別效果的優越性。
在后續的研究工作中,可以進一步研究更小的樣本長度以及加密分組長度對識別準確率的影響,并且嘗試對CBC、CFB等復雜工作模式開展研究,繼續優化密文特征選擇和特征處理過程。
參考文獻
[1] Maqsood F, Ahmed M, Ali M M, et al. Cryptography: a comparative analysis for modern techniques[J]. International Journal of Advanced Computer Science and Applications, 2017, 8(6).
[2] 李瑞林. 分組密碼的分析與設計[D]. 國防科學技術大學, 2011.
[3] 趙志誠. 基于機器學習的密碼體制識別研究[D]. 鄭州: 信息工程大學, 2018.
[4] 張永強, 李順波, 屈帥, et al. NIST隨機性檢測方法及應用[J]. 電腦知識與技術, 2014, (9X):6064-6066.
[5] GM/T0005-2021, 隨機性檢測規范[S].
[6] 付文博, 孫濤, 梁藉, et al. 深度學習原理及應用綜述[J]. 計算機科學, 2018, 45(B06):11-15.
[7] 黃良韜, 趙志誠, 趙亞群. 基于隨機森林的密碼體制分層識別方案[J]. 計算機學報, 2018, 41(2):382-399.
[8] 趙志誠, 趙亞群, 劉鳳梅. Grain-128算法的密碼體制識別研究[J]. 信息工程大學學報, 2019, 20(1):102-110.
[9] 趙志誠, 趙亞群, 劉鳳梅. 基于隨機性測試的分組密碼體制識別方案[J]. 密碼學報, 2019, 6(2):177-190.
[10] 紀文桃, 李媛媛, 秦寶東. 基于隨機性特征的SM4分組密碼體制識別[J]. Application Research of Computers/Jisuanji Yingyong Yanjiu, 2021, 38(9).
[11] 曹莉茹. 基于深度學習的密碼算法識別研究[D]. 電子科技大學, 2021.
[12] 劉節威, 王鋼, 顏培志, et al. 基于CNN的國產商用分組密碼算法識別研究[J]. 網絡安全與數據治理, 2022, 41(9):7-14.
[13] Ruiqi X, Manman L, Shaozhen C. Encryption Modes Identification of Block Ciphers based on Machine Learning[J]. International Journal of Network Security & Its Applications, 2022, 14(5):1-10.
[14] Yuan K, Huang Y, Li J, et al. A block cipher algorithm identification scheme based on hybrid random forest and logistic regression model[J]. Neural Processing Letters, 2023, 55(3):3185-3203.
[15] 夏銳琪, 李曼曼, 陳少真. 基于機器學習的分組密碼結構識別[J]. 網絡與信息安全學報, 2023, 9(03):79-89.
[16] 張運理, 石元兵, 明爽, et al. 唯密文場景下的分組密碼算法識別方法[J]. 通信技術, 2024, (002):057-064.
[17] 陳慧鋒. 基于深度學習的輕量級分組密碼研究[D]. 中國礦業大學, 2023. DOI:10.27623/d.cnki.gzkyu.2023.003102.
[18] 李洪超. 基于密文特征的密碼算法識別研究[D]. 西安: 西安電子科技大學, 2018.
[19] LI Z-s, YAO X, LIU Z-g, et al. Feature selection algorithm based on LightGBM[J]. Journal of Northeastern University (Natural Science), 2021, 42(12):1688-1694.
[20] Parmar A, Katariya R, Patel V. A review on random forest: An ensemble classifier[C]. Proceedings of the International conference on intelligent data communication technologies and internet of things (ICICI) 2018, F, 2019. Springer.
[21] Vens C, Costa F. Random forest based feature induction[C]. Proceedings of the 2011 IEEE 11th international conference on data mining, F, 2011. IEEE.
[22] Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree[J]. Advances in neural information processing systems, 2017, 30.
[23] Wang D-n, Li L, Zhao D. Corporate finance risk prediction based on LightGBM[J]. Information Sciences, 2022, 602:259-268.
[24] Al Daoud E. Comparison between XGBoost, LightGBM and CatBoost using a home credit dataset[J]. International Journal of Computer and Information Engineering, 2019, 13(1):6-10.
[25] Hancock J, Khoshgoftaar T M. Leveraging lightgbm for categorical big data[C]. Proceedings of the 2021 IEEE Seventh International Conference on Big Data Computing Service and Applications (BigDataService), F, 2021. IEEE.
[26] Yuan K, Yu D, Feng J, et al. A block cipher algorithm identification scheme based on hybrid k-nearest neighbor and random forest algorithm[J]. PeerJ Computer Science, 2022, 8:e1110.
英文摘要
Identification Scheme for Block Cipher Algorithms Based on RF-LightGBM
DONG Xiuze YANG Honggang HU Yifan YU Gengchen
Beijing Electronic Science and Technology Institute, Beijing 100070, P.R. China
Abstract: Cryptographic algorithm identification holds significant importance in the cryptanalysis field. In mainstream block cipher algorithm identifying schemes, the ciphertext feature extraction is typically based on randomness detection standards. To address the need for identifying short samples and further improve the identification accuracy, an identification scheme for block cipher systems based on RF-LightGBM is proposed in this paper. Firstly, ciphertext features are extracted according to the GM/T 0005-2021 randomness detection standard, and the Random Forest algorithm is utilized to rank and filter the importance of high-dimensional data. Then, feature vectors are used to train a LightGBM model to construct a cryptographic algorithm classifier for identification. This method fulfills the need for efficiently identifying unknown ciphertexts under short sample conditions. The proposed scheme achieves an overall accuracy enhancement of about 12% in pairwise identification experiments, outperforming existing schemes. Multi-classification experiments show that the accuracy rates exceed 73%, verifying the effectiveness and superiority of the proposed scheme in block cipher algorithms identification, which provides a valuable reference for future cryptographic algorithm identifying under more complex encryption modes.
Keywords: block cipher; machine learning; randomness detection; cryptographic algorithm identification; LightGBM




