摘要:書院是我國古代獨特的教育機構,而《中國書院辭典》作為記載書院的重要資料,收納自唐代至清代全國有史可考的書院多達1600余所。為全面、系統地整理與提取有效數據,文章在對事件抽取
書院是我國古代獨特的教育機構,而《中國書院辭典》作為記載書院的重要資料,收納自唐代至清代全國有史可考的書院多達1600余所。為全面、系統地整理與提取有效數據,文章在對事件抽取各類模式與方法綜述的基礎上,探索出綜合旋轉式位置編碼與圖遞歸檢索的方法以抽取書院的事件信息:利用RoFormerV2模型對絕對位置進行編碼,使每個向量附帶相對位置信息,之后借助全局歸一化思想通過嵌套實體識別模型GlobalPointer和完全子圖搜索方式遞歸查找事件類型與論元。在《中國書院辭典》上進行的實驗表明,該方法能有效融合向量的位置和語義信息并對論元間的關聯性進行建模,克服了長文本引發的信息缺失與事件論元的嵌套問題,并具備良好的外推性。
關鍵詞:中國書院辭典;事件抽取;RoFormerV2;GlobalPointer;圖遞歸檢索
論文《融合旋轉式位置編碼與圖遞歸檢索方法的書院事件抽取研究》發表在《大學圖書館學報》,版權歸《大學圖書館學報》所有。本文來自網絡平臺,僅供參考。
書院作為東亞儒家文明的典型形態,也作為我國文化中一種獨具特色的教育模式,以教書、藏書、著書、刻書為主體,自唐代至晚清已傳承千余年。由季嘯風所著的《中國書院辭典》則記載了千年以來我國書院大到初創建立、改制廢除,小到學制學規、著書刻書等一系列重要史料,若能高效準確提取出辭典里關鍵的知識元素,如地點、朝代、人物、官職、行為等信息,將不僅可以展現儒家文化的區域性差異,同時還可揭示其構建主體的階級變化。
當前在信息抽取層面,依據信息要點的不同可分為實體、關系、事件,在此基礎上信息抽取的子任務進一步被劃分為命名實體識別、關系抽取、事件抽取。文章選用的事件抽取任務本質屬于多元關系抽取,是將文本根據語義描述差異歸納為各類事件并進行細粒度識別,幫助學者快速識別文本數據中的重要信息,歸納整理以便用于后期事理圖譜及信息檢索系統的構建。
事件抽取作為自然語言處理領域的重要分支之一,最早可追溯至上世紀90年代,美國國家標準與技術研究所召開的自動內容提取會議(Automatic Content Extraction, ACE)將事件定義為:在特定時間、地點中,由一個或多個角色引發的一個或多個動作造成了事物狀態的改變,從而推動了該任務的發展。現階段,大多數的事件抽取任務建立在句子級基礎上,常見的BERT、RoBERTa、ELECTRA均使用了絕對位置編碼,使文本的最大輸入長度限制為512個字符。在對《中國書院辭典》這一文本集進行梳理后,發現該類語料存在兩大特征:一方面,詞條以書院為單位,部分詞條字數超出常規預訓練模型的文本輸入要求,而超出最大長度的粗暴截斷致使句子級的預訓練模型不能準確對其建模;另一方面,語料存在不同事件類型共用相同觸發詞的現象,即一個觸發詞可表征多個事件類型,而傳統的事件抽取任務將觸發詞識別視作序列標注任務,忽略了觸發詞和事件論元間的相互關聯。
為了解決上述問題,文章融合旋轉式位置編碼與圖遞歸檢索方法,并基于《中國書院辭典》的內容構建一種可處理長文本的事件抽取方法,具體貢獻如下:
1. 針對絕對位置編碼的最長輸入截斷現象,使用基于旋轉式位置編碼的RoFormerV2模型,利用旋轉矩陣對絕對位置進行編碼,使每個向量附帶相對位置信息,令其具有更好的外推性。
2. 為了解決事件論元嵌套與論元間的關聯性問題,接入了圖遞歸檢索模塊GPLinker。該模塊通過一個嵌套實體識別模型GlobalPointer將識別得到的(事件類型,觸發詞,具體觸發詞)和(事件類型,論元角色,論元)作為完全圖的相鄰節點,用遞歸檢索策略進行抽取,只有相同事件類型的論元和觸發詞才會被關聯上,解決了觸發詞的誤識別問題。
3. 基于事件抽取結果,利用時空統計法梳理明清時期書院創辦的空間分布特征和建設力量差異,論證明清兩代書院創辦呈現的特征分析。
1 相關研究
1.1 事件抽取模式
事件抽取指在確定的語句結構中,從句子或篇章文本中識別出符合要求的事件信息,具體可細分為觸發詞識別、事件類型分類、論元提取、論元角色分類四個子任務,前兩者可稱作事件檢測,后兩者則合并為元素識別。
一般來說,當子任務先后串行提取時被視作是管道型抽取,即先識別觸發詞并判斷相應的事件類型,再檢測論元確定其論元角色。比較典型的有陳(Chen)等人的動態多池化卷積神經網絡(DMCNN)模型,在事件檢測階段將句子經過卷積得到的特征分段進行池化,以捕獲句子不同部位的突出特征,然后在元素識別階段根據觸發詞與事件論元的位置將各部分池化的結果拼接構成句級特征從而抽取;郭鑫等人提出三階段管道式方法,先用無監督方式對事件類型分類,接著進行事件句提取,最后利用BiLSTM-CRF模型識別并拼接事件論元;王(Wang)等人構建基于問答的篇章級核心事件抽取模型,先檢測事件類型,再利用問答模式的BTBiLSTM提取事件論元,最后融合并選擇得分最高的核心事件。
但是,上述管道型抽取的弊端較為明顯,下游任務對上游抽取結果的依賴性決定了錯誤容易產生級聯,一旦事件檢測失誤,對應的論元識別效果也將大大降低。為了解決這類問題,進而衍生了聯合型的抽取方式,該模式利用聯合提取算法同時預測事件類型與具體論元,克服了級聯錯誤的發生。李(Li)等人提出了結合局部和全局特征的結構化預測框架,可同時提取觸發詞和論元;阮(Nguyen)等人提出基于雙向遞歸神經網絡的聯合框架,引入內存矩陣,以此捕獲論元角色和觸發詞的依賴關系;葛軍偉等人利用BiLSTM模型提取段落特征,采用自注意力機制獲取上下文交互信息,融合文檔序列更新語義表示,最后采用序列標注提取論元和事件類型。
1.2 事件抽取方法
事件抽取最初始于基于模式匹配的方法,抽取模板是由專家融合專業背景知識和不同的句法、語法特征來人工設計。隨著算法技術的發展和算力水平的提升,相繼涌現出基于機器學習、深度學習的方式。
基于機器學習的事件抽取本質是將抽取轉化為分類問題,運用支持向量機、條件隨機場、隱馬爾可夫模型等算法構建分類器進行事件分類與論元識別。貝塔德(Bethard)和馬丁(Martin)結合形態句法特征和支持向量機的方法構建事件檢測系統;洛朗(Llorens)等人使用條件隨機場算法,利用各類句法和語義角色特征進行事件識別與分類;博羅什(Boros)等人通過無監督學習獲得詞向量特征表示,使用決策樹分類抽取具體的事件論元。
機器學習弱于語義特征的學習,不擅長處理復雜的語義關系,而深度學習的方式恰好彌補了這一缺陷。張(Zhang)等人充分利用跳窗卷積神經網絡提取全局的結構化特征,再通過波束搜索尋找句子,提高觸發詞識別的準確性;段(Duan)等人的文檔級循環神經網絡(DLRNN)模型,通過分布式向量的文檔表示來提取跨句線索,連接文檔向量和詞嵌入特征并將其作為BiLSTM模型的輸入;薛頌東等人采用多粒度閱讀器實現多層次語義編碼,通過圖注意力網絡獲取實體對的全局與局部關系,構造剪枝完全圖為觸發器捕捉事件和論元。
在深度學習領域,預訓練模型也已成為一種強有力的技術手段。它的出現源于現實中缺乏足夠的標注數據,而深度學習模型往往需要大量數據來訓練從而避免過擬合問題,因此使用預訓練模型汲取在大規模數據集上學習到的固定特征來幫助解決小樣本難題。其中,位置編碼記錄了字詞在文本中的順序,使句子變為具備前因后果的字詞序列,預訓練模型里常見的編碼方式有絕對位置編碼、相對位置編碼。絕對位置編碼基于位置嵌入,對每個位置都分配了一個唯一的位置向量,這種向量固定的編碼方式對短序列較為友好,但不擅長處理超過模型訓練長度的長序列文本,田三川與張虎在事件抽取研究中用到的BERT和RoBERTa都屬于絕對位置編碼。相對位置編碼基于相對位置,給每個位置賦予一個表示該位置與其他位置相對距離的偏移量,這類編碼方式可用于處理長序列,并在上下文保持一致性,較為典型的有XLNET、T5模型。然而,當前的相對位置編碼大多基于注意力矩陣進行操作,而本文所用到的旋轉式位置編碼RoFormerV2事先不用計算注意力矩陣,而是以內積形式使向量附帶相對位置信息,該編碼方式存在兩大優點:一是擅長處理長文本的語義信息,二則是捕捉長句中的相似結構和重復模式。本文所使用的《中國書院辭典》存在部分詞條超出常規預訓練最大文本長度的情況,且辭典本身是將知識信息經過系統化整理和歸納后的產物,存在一定的制式性,適用于RoFormerV2捕捉對稱性數據的特點。
2 研究方法
2.1 模型架構
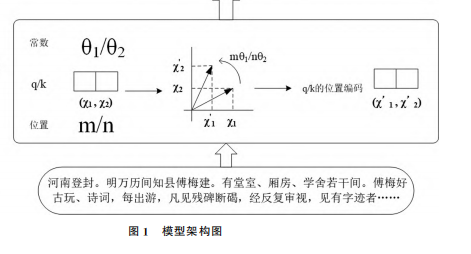
文章使用的融合旋轉式位置編碼與圖遞歸檢索方法的模型架構如圖1所示,該模型包括基于旋轉式位置編碼的預訓練模型RoFormerV2、由GlobalPointer和完全圖組成的圖遞歸檢索模塊GPLinker兩部分,用以聯合抽取事件類型、觸發詞、論元角色及論元。
當文本序列輸入到模型中時,預訓練模型RoFormerV2依據特有的旋轉位置嵌入(Rotary Position Embedding, RoPE)方法,將transformer里位置為m、n的query、key(簡稱q、k)向量分別乘以旋轉矩陣得到變換后的q、k向量,而輸入的文本序列也將充分利用向量的相對位置信息,進一步從語義上獲取語料庫的上下文特征,形成書院數據的向量表示。
上述向量表示輸入至圖遞歸檢索模塊GPLinker時,會先被GlobalPointer這一嵌套實體識別模型進行首尾標注,重點標注事件類型、論元角色和觸發詞。GlobalPointer在記錄位置的同時也將“(事件類型,論元角色)、(事件類型,觸發詞)”各自組合形成實體加以識別,識別后的(事件類型,論元角色/觸發詞,論元/具體觸發詞)會被送進完全圖作為圖中的節點,相同事件類型成為相鄰節點,使完全子圖搜索轉化為對同一“論元/具體觸發詞”所對應的不同事件的遞歸檢索。
2.2 旋轉式位置編碼
RoFormerV2模型建立在RoFormer模型基礎上,出發點是用絕對位置與旋轉矩陣的乘積進行編碼,以達到用“絕對位置編碼方式實現相對位置編碼”的效果。為結合相對位置信息,RoFormer模型先給transformer的q、k添加絕對位置信息m、n將其轉為q_m和k_n,用函數g表示q_m和k_n的內積,其中x_m和x_n是詞嵌入向量,m-n是它們的相對位置信息,最終目標是找到一種等效機制以符合公式(1)的函數關系:
(f_q(x_m, m), f_k(x_n, n)) = g(x_m, x_n, m-n) quad (1)
當x_i in R^d,由于內積滿足線性疊加性,我們將d維空間拆分成d/2個子空間并以內積形式進行線性拼接,向量x和矩陣R_{ heta, m}^d相乘做空間變換映射成新的向量x,旋轉角度為m heta_i,計算公式如下:
�egin{align*}
R_{ heta, m}^d x &= �egin{pmatrix} x_1 \ x_2 \ x_3 \ x_4 \ vdots \ x_{d-1} \ x_d end{pmatrix} otimes �egin{pmatrix} cos m heta_1 \ cos m heta_1 \ cos m heta_2 \ cos m heta_2 \ vdots \ cos m heta_{d/2} \ cos m heta_{d/2} end{pmatrix} + �egin{pmatrix} -x_2 \ x_1 \ -x_4 \ x_3 \ vdots \ -x_d \ x_{d-1} end{pmatrix} otimes �egin{pmatrix} sin m heta_1 \ sin m heta_1 \ sin m heta_2 \ sin m heta_2 \ vdots \ sin m heta_{d/2} \ sin m heta_{d/2} end{pmatrix}
end{align*} quad (2)
具體來說,旋轉位置嵌入(RoPE)指將transformer的詞嵌入向量q、k旋轉到其位置索引的角度倍數上,正是由于這種獨特的位置編碼技術使RoFormer模型可以附帶位置間的相對關系,進而更好地解決一詞多義引發的易混淆問題。
相比RoFormer模型,本文采用的RoFormerV2模型做了如下改動:在結構上,RoFormerV2模型去掉了所有偏置項,并將transformer常用的層級歸一化調整為均方差層歸一化(Root Mean Square Layer Normalization, RMS Norm),刪除RMS Norm的gamma參數;無監督訓練方面,RoFormerV2模型從零開始共使用280G數據進行訓練,RoFormer模型則在RoBERTa權重基礎上,用到的數據僅有30G左右;有監督訓練方面,RoFormerV2模型增添了77個總計20G的標注數據集,進行92項如文本分類、指代消解、閱讀理解、信息抽取等自然語言處理任務,達到了速度和效果的提升。
2.3 圖遞歸檢索模塊
圖遞歸檢索模塊將觸發詞識別、事件類型分類、論元提取、論元角色分類四個子任務轉化為一個聯合抽取任務,使觸發詞作為事件的論元角色,對“(事件類型,論元角色,論元)”的識別轉為對“(事件類型,論元角色/觸發詞,論元/具體觸發詞)”的組合提取。為有效完成事件抽取任務,本文的圖遞歸檢索模塊GPLinker主要由利用全局歸一化的GlobalPointer和完全子圖搜索兩部分構成。
傳統的指針網絡一般分別識別實體的開始位置和結束位置,造成訓練和預測的不一致性,而GlobalPointer的設計思想是將實體的開始位置和結束位置作為一個整體處理。假設長度為n的文本序列經過RoFormerV2模型編碼后變為向量序列[h_1, h_2, cdots, h_n],對于區域跨度為s[i:j]的實體類型alpha,將通過公式(3)、(4)兩個線性變換得到序列向量的開始位置q_{i,alpha}和結束位置k_{j,alpha},其中alpha對應“(事件類型,論元角色/觸發詞)”這一組合,W_q和W_k為權重矩陣,b_q和b_k是偏置項,實體類型alpha的評分函數如公式(5)所示:
q_{i, alpha} = W_{q, alpha} h_i + b_{q, alpha} quad (3)
k_{j, alpha} = W_{k, alpha} h_j + b_{k, alpha} quad (4)
s_alpha(i, j) = q_{i,alpha}^T k_{j,alpha} quad (5)
s_alpha(i, j)是用q_{i,alpha}和k_{j,alpha}的內積來表示從第i個到第j個序列所組成的連續字符串,打分最高的實體將被選中。
完全子圖搜索步驟為:對每一個文本,首先列出所有節點對,如果節點對都相鄰,表示該圖符合完全圖標準,可直接返回。若節點對不相鄰,則針對每一對不相鄰的節點都分別列出與之相鄰的節點集形成子圖,再對每一個子圖遞歸檢索,從而獲得該文本序列涵蓋的所有事件論元和具體觸發詞。
3 實驗結果分析
3.1 語料來源與預處理
(1) 標注流程
數據集來源于《中國書院辭典》,標注工具為Excel,標注者僅筆者本人,整體的標注流程包括數據預處理、數據試標注、正式標注、標注結果復驗四個階段。
在數據預處理階段,主要完成對文件的格式轉換與數據清洗,包含將pdf文件轉為word文檔,檢查是否有錯別字或文字疏漏,刪除空白行,依照省份、書院名稱對每個詞條進行歸類梳理。
在數據試標注階段,為了能基于文本的不同主題對事件類型進行歸納,筆者先標注100條數據,檢查事件類型及論元角色前后是否一致、是否已形成一定規則,可供后續標注做參照。若發現當前數據量過少,標注出的事件類型尚無法覆蓋全集,將繼續增加試標注數據,直至后續標注不會出現新的事件類型,此刻可對當前已標注出的規范進行總結。
在正式標注階段,將依據試標注總結出的規律對全部文本進行事件類型、觸發詞、論元角色和具體論元的提取。
在標注結果復驗階段,由于目標數據集需包含觸發詞和論元的起始位,因此用Excel內置的SEARCH函數查找詞語位置,再從第一條開始復查,復查內容包括確定起始位是否準確(同一詞條可能含有多個相同的觸發詞,但SEARCH函數只顯示第一個字符串匹配的位置),檢查事件類型的標注是否遵循規范,核驗論元標注是否有遺漏。
(2) 事件類型、論元角色的設置
《中國書院辭典》收錄了唐代至清代全國各地有史可考的1626多所書院資料,對揭示區域性儒家文化的歷史傳承具有重要價值。該數據集從內容收錄角度,既包含動態的敘事性事件,如書院歷經朝代更迭所發生的創辦、修繕、廢除等事件,也涵蓋靜態的概念性信息,用于描述對象固定不變的狀態,如教學管理制度、書院衍生文獻。
從動態的敘事性角度來看,書院數據集覆蓋創辦、捐建修繕、捐田捐資、諭賞賜額、毀壞廢除、維護保存、講學論道等七個事件類型;從靜態的概念性角度而言,書院數據集又有教學內容及管理制度、衍生文獻兩類。
在對文本內容總結的基礎上,標注形成9個事件類型,總計8740條事件數據,標注的事件類型、論元角色及數量情況如表1所示。
表1 事件類型、論元角色的設置
事件類型(數量) 論元角色(數量)
創辦(1626) 所在地(1626)、初建朝代(1583)、初建年號(1481)、公元(1238)、創辦方身份(1473)、創辦人名(1527)、代表性建筑(447)、創建原因(117)、書院別稱(173)、書院前身(305)
捐建修繕(4461) 修繕朝代(597)、修繕年號(4211)、公元(2727)、修繕方身份(2999)、修繕方人名(2983)、具體措施(3568)、修繕原因(205)
捐田捐資(453) 捐置年號(448)、公元(241)、捐置方身份(431)、捐置方人名(429)、捐置措施(431)
諭賞賜額(88) 諭賞時間(82)、諭賞內容(87)
毀壞廢除(693) 廢除時間(691)、廢除原因(426)
維護保存(266) 維護時間(20)、書院現名(266)
講學論道(608) 講學時間(246)、主講人(640)、講學內容(98)
教學內容及管理制度(310) 變動時間(119)、章程(239)、課程(129)
衍生文獻(235) 朝代(75)、作者(156)、文獻名稱(246)
(3) 缺省補全策略
在標注過程中,筆者發現少量數據存在時間、地點、人名等關鍵詞缺省,書院擬建未成,多個時間論元同時存在的情況。針對上述數據存在的問題,具體處理細則如下:
1. 時間、地點的缺省補全:時間、地點的上下文引用情況較多,出現缺省的現象也最為普遍。由于漢語篇章上下文連貫度較高,描述事件發生的時間要素、地點要素出現位置相對靠近,時空要素在約束本句的同時有時還會約束后續事件。因此,在時間要素、地點要素的補全策略中,往往使用上一段、上一句的先驗時間和地點進行補全。
2. 人名的缺省補全:人名的缺省一般出現在上文已提及人物的具體名稱,為避免句子出現重復,提高其表達效率,文章常會出現人物姓或名的缺失,此時可根據上下文進行補全。
3. 不標注無效的事件信息:本文主要記錄遷建修繕成功的事件實例,因此書院擬建而未成的內容將不做標注。
4. 多時間要素現象:針對多個時間要素同時存在的情形,本文將只記錄事件發生的起始時間。
(4) 詞條的字數分布情況
標注的詞條字數分布情況如表2所示,各書院詞條字數由18字至2007字不等,絕大多的書院詞條超出128字,多個單句構成的長文本容易造成信息提取缺失。其中94.1%的詞條字數小于512字,滿足以絕對位置編碼的預訓練模型的最大輸入長度,而剩余5.9%則超出一般預訓練模型的訓練范圍。
表2 詞條的字數分布情況
字數區間 書院詞條數 詞條字數占比(%)
0-128 328 20.17
128-256 787 48.40
256-512 415 25.52
512-1024 87 5.35
1024-2048 9 0.55
3.2 實驗參數及評價指標的設置
為有效驗證研究方法的有效性,本文選取了近年來以絕對位置編碼為主的BERT、RoBERTa、ELECTRA預訓練模型,對比RoformerV2模型在同等文本序列識別性能的提升情況,同時在下游設置傳統的CRF模型做參照,以驗證GPLinker的抽取效果。實驗使用的BERT模型為谷歌提供的bert-base-chinese,中文版本的RoBERTa模型與ELECTRA模型為哈爾濱工業大學·訊飛語言認知計算聯合實驗室發布的RoBERTa-wwm-ext、ELECTRA-base。
實驗采用的GPU是NVIDIA Tesla V100 16GB,實驗環境為Python 3.7, Tensorflow 2.0, Keras 2.3.1,詳細的參數設置如表3所示。
表3 模型參數設置
參數名 參數值
epochs 35
batch_size 8
crf_lr_multiplier 100
learning_rate 1e-5
maxlen 512
文章的事件抽取模型選用準確率(Precision)、召回率(Recall)和F1值(F1-score)作為評價指標,具體計算公式為:
P = frac{ ext{識別正確的論元數}}{ ext{機器識別的論元數}} quad (6)
R = frac{ ext{識別正確的論元數}}{ ext{人工標注的論元數}} quad (7)
F1 = frac{2 imes P imes R}{P + R} quad (8)
3.3 實驗結果分析
實驗分別設置BERT、RoBERTa、ELECTRA、RoFormerV2四個預訓練模型結合CRF、GPLinker模型,按照8:1:1劃分訓練集、驗證集與測試集,單次epoch所耗時間及模型測試結果如表4所示。
表4 不同模型的效率比較
編號 實驗模型 計算時間(s) P(%) R(%) F1(%)
① BERT-CRF 108 82.78 80.44 81.60
② RoBERTa-CRF 114 82.49 81.39 81.93
③ ELECTRA-CRF 110 80.76 80.24 80.50
④ RoFormerV2-CRF 318 83.01 83.17 83.09
⑤ BERT-GPLinker 63 89.73 87.25 88.47
⑥ RoBERTa-GPLinker 70 89.98 87.46 88.70
⑦ ELECTRA-GPLinker 64 87.57 88.59 88.08
⑧ RoFormerV2-GPLinker 90 91.15 87.77 89.43
在位置編碼方面,本文采用旋轉式位置編碼的實驗④、⑧效果均優于使用絕對位置編碼的實驗組別,實驗④相比①、②、③在F1值分別提升了1.49、1.16、2.59個百分點,實驗⑧較⑤、⑥、⑦在F1值分別提升了0.96、0.73、1.35個百分點,但單次epoch耗費時間較多。由于attention層本身不具備識別位置的能力,常規的BERT、RoBERTa、ELECTRA模型均顯式增加預先定義好的序列位置,而RoFormerV2模型用內積形式添加向量的相對位置,使底層transformer結構可以同時提取語義和位置信息。實驗結果證明,旋轉式位置編碼的RoFormerV2模型具備較好的上下文特征提取能力,更適用于《中國書院辭典》所出現的長文本序列。
在下游的事件抽取層面,使用圖遞歸檢索模塊GPLinker的實驗⑤、⑥、⑦、⑧取得了更好的識別效果,與預訓練模型后接CRF的實驗①、②、③、④相比,在F1值上分別提升了6.87、6.77、7.58、6.34個百分點,單次epoch耗費時間減少,整體計算效率提高。說明GPLinker的GlobalPointer將實體開始位置和結束位置作為一個整體處理,且后續的完全子圖搜索以“首-首”匹配和“尾-尾”匹配模型來構建論元關系,比CRF利用特征模板計算聯合概率的方法更能識別實體的邊界,進而提升模型的性能。
RoFormerV2-GPLinker模型基于《中國書院辭典》數據集上35個epoch的loss曲線顯示,該模型loss值在前20個epoch波動比較明顯,在后續訓練過程逐漸趨于穩定。驗證集上的F1值在第3個epoch之后已逐漸趨于平衡,結合圖4中的信息,可知在第20至35個epoch之間,模型趨近收斂。
3.4 RoFormerV2-GPLinker模型的外推性測試
依前文所述,RoFormerV2模型具備良好的外推性,在理論層面,旋轉式位置編碼能處理任意長度的文本序列,而3.3節的實驗由于受限于BERT、RoBERTa、ELECTRA模型的最大文本長度,訓練時的參數max_len只能設置為512,無法充分對數據集進行建模。為進一步評估在長文本的外推性能,文章增添了RoFormerV2-GPLinker模型于256、512、1024、2048四種文本長度的實驗。實驗結果表明,隨著模型所設置的最大文本長度的遞增,RoFormerV2-GPLinker模型能建模的文本數據也在增多,使得F1值不斷提高。旋轉式位置編碼即使在文本長度超過512個字符時,識別效果仍能保持提升,該模型通過引入相對位置信息,借助圖遞歸檢索方法準確識別實體邊界,提取嵌套事件,從而完善對長文本的編碼與建模能力,具備較優的外推性。
3.5 案例分析
圖8展示了RoFormerV2-GPLinker模型和RoBERTa-CRF模型對“南臺書院”抽取的結果分析,所有準確識別的結果都用黃色底紋標出。從圖中可以觀察到,“光緒二十四年受時務學堂影響,始設立史學、掌故、輿地等課程”的觸發詞為“設立”,這一觸發詞大多對應“創辦”和“捐建修繕”,而本句其實屬于“教學內容及管理制度”類型。由抽取結果可知,RoBERTa-CRF模型將其分為“捐建修繕”類型,涉及課程變更的部分被列入“具體措施”的事件論元,而RoFormerV2-GPLinker模型卻能準確識別“設立”和課程內容同屬于“教學內容及管理制度”的事件類型,是因為GPLinker將觸發詞和論元列為相鄰節點進行遞歸抽取,降低了誤識概率。
4 書院文本事件抽取結果的可視化分析
4.1 明清書院創辦的空間分布特征
在書院發展史上,明代承前啟后,清代普及流變,明清時期的書院無論是在數目還是規模都占據主要地位,本文梳理出《中國書院辭典》明清時期“創辦”類型所覆蓋的地級市名稱進而得出書院創辦的空間分布統計表。由于該辭典成書于1996年,次年中國設立重慶直轄市和香港特別行政區,1999年又增設澳門行政區,因此文章依據最新行政區劃對辭典里的部分省市進行了校正。
據《中國書院辭典》正文所記,明代創辦的書院有313所,清代創辦的有1010所。由表5可知,明清兩代書院的創建均呈現明顯的不平衡性,東北、西北地區書院新建數遠遠少于江南與東南沿海地區。較明代而言,清代書院在原有基礎上進一步普及,創辦趨勢一直呈不斷發展壯大之勢,尤以河南、安徽、廣東、四川、湖南、云南、浙江等省為甚。
明初官學興盛,朝廷奉行“治國以教化為先,教化以學校為本”的思想,革罷書院,大力倡導官學教育,使書院發展陷入沉寂階段。明代中期,王、湛之學興起,自正德至嘉靖年間,湛若水的足跡遍及廣東、南直隸(江蘇、安徽、上海)等地,王、湛弟子及后生更是于各地開講會、建書院,致使書院興建一時大盛。明代后期,國勢衰敗、政局混亂,朝廷禁毀書院,書院由盛轉衰,與明王朝一并走向低谷。
清初順治時期,為抑制明末民族主義思想,詔令“不許別創書院,群聚徒黨”,至康熙年間,朝廷的書院政策逐步放寬,各地紛紛爭相興復書院。雍正、乾隆時期呈現全盛局面,書院步入大力發展期,新建數量眾多,涉及區域也更加廣泛。道光、咸豐年間,外遭殖民侵略、內歷天平天國起義,書院新建的氣勢漸弱,但仍有發展。之后,洋務運動興起,西學東漸的思想使書院進入高速普及階段,覆蓋范圍較廣,以略偏僻的廣西地區為例,同治、光緒年間僅書院新建就有15所。
4.2 明清書院建設力量分析
明清兩朝官制存在一定差異,明代地方各級行政機構包含省、府、州、縣四級,清代實行省、府(州)、縣三級行政區劃,但在行政級別上又在省和府之間增設道員,清代的州也分為直隸州和散州,直隸州隸屬于省,散州則隸屬于道或府。文章統計《中國書院辭典》里“創辦”類型涵蓋的“創辦方身份”,從建設力量可分為官方與民間,其中官方力量有中央和地方。清代地方上雖是三級區劃,但由于道員名義上與知府平級,行政級別卻有隸屬關系,而知州也分為直隸州和散州,直隸州知州地位低于知府,散州知州又略高于知縣,因此文章中清代的道與州沒有列為三級行政區劃之一,而是作單獨分析。
明代書院建設主要依賴官方力量,中央政府中的都察院御史、六部尚書、六科給事中等,省級的巡撫、布政使司、按察使司官員,府級的知府、同知,縣級的知縣、縣丞都曾作為書院創辦的中堅力量,縣級地方官的人數最多,中央、省、府的官員數差異不大,民間力量較少,主要由當地邑人、邑紳組成。在清代書院建設中,依舊依循官辦為主、民辦為輔的格局,與明代不同的主要有三點:第一,中央級別官員占比在減少,省、道、府、州、縣級官員參與變多,說明地方官員在書院創辦問題上呈積極態度,使地方官力成為影響書院發展的主要力量;第二,清代知縣作為書院創辦方的占比在大幅增加,經統計共有422位知縣參與書院興建,體現縣級官員在當地對公共資源的直接管控、分配具備一定的自主權,對書院發展起到重要推動作用;第三,清代的民間力量多了商人和外籍人士的身影,并造就了教會書院這一新的類別,是清代書院的一大特征。
從民間力量的分布來看,創辦者的身份大致有以下四種類型:明代參與書院創辦的民間力量主要由士人與邑人組成,士人多是貢士、進士等科舉致仕者,邑人則為當地的儒士、邑紳,他們有的為接續道統、追憶先輩,有的為造福鄉里、啟迪后生。清代書院創辦的民間力量仍以士人和邑人為主體,但書院的教學理念卻出現了分化,逐步形成博習漢學和經史詞章,教授程朱理學,提倡經世致用三類書院,其中以經世致用為指導思想的書院是為結合中西之力,嘗試將古老的書院制度和西方近代教育體制接軌,意在推古求新。除士人與邑人群體外,隨著商品經濟的發展,清代商人的經濟實力進一步加強,商人興資辦學的情況屢屢出現,如鹽商汪鳴瑞和都轉運鹽使高熊征集財建紫陽書院,蘆商查為義、運使盧見曾建問津書院,都是為子弟舍商而士創造條件。同時,清代書院的創辦方也出現了來自美、英、德、法各國的外籍人士,書院所授課程各有不同,有英國長老會牧師莫偉良創立的瞽目書院,專收盲童,教以盲文、算術、音樂等科;美國基督教公理會傳教士婁戴德在通縣城內建立的八境神學院,課程以圣經、漢文和英文為主;德國基督教同善會傳教士尉禮賢創辦的禮賢書院,部分課程用德語授課,搜集形象教具并建立化學和物理室。
5 結語
文章綜合旋轉式位置編碼與圖遞歸檢索方法構建了書院事件抽取模型,利用RoFormerV2模型解決長文本的截斷現象,借助GlobalPointer、完全子圖搜索策略化解多論元的嵌套及論元間的關聯性問題。研究結果證明,該模型能有效融合向量的位置和語義信息,在事件抽取任務上較基線模型取得了較優結果,并在文本長度超過512個字符時,模型識別效果仍能保持提升。進一步地,根據《中國書院辭典》提取出的事件類型及論元梳理并分析明清書院創辦的空間分布及建設力量,發現明清兩代書院的創辦在區域上均呈現明顯的不平衡性,并且都遵循官辦為主、民辦為輔的格局,但具體在書院覆蓋范圍和創辦人群分布上仍存在較大差異。
文章提出的事件抽取模型融合了向量的位置特征,以“首-首”匹配和“尾-尾”匹配方式來構建論元關系形成完全圖,雖然取得了一定的效果,但未來依然有許多需改進之處。就模型本身而言,可考慮融合更多的詞特征信息提升模型性能,去除冗余參數優化模型結構,使模型更輕量化。而在《中國書院辭典》數據方面,未來將輔以更多的古籍文獻,對剩余事件類型進行深入分析研究,以挖掘書院的教育活動及其與地方社會的聯系。
參考文獻
1. 季嘯風. 中國書院辭典[M]. 杭州: 浙江教育出版社, 1996.
2. Devlin J, Chang M, Lee K, et al. BERT: pre-training of deep bi-directional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA, 2019: 4171-4186.
3. Cui Y M, Che W X, Liu T, et al. Pre-training with whole word masking for Chinese BERT[J]. IEEE-ACM Transactions on Audio Speech and Language Processing, 2021: 3504-3514.
4. Clark K, Luong M T, Le Q V, et al. ELECTRA: pre-training text encoders as discriminators rather than generators[C]//Proceedings of the 8th International Conference on Learning Representation. 2020: 1-18.
5. Su J L, Murtadha A, Pan S, et al. Global pointer: novel efficient span-based approach for named entity recognition[EB/OL]. [2024-05-05]. https://arxiv.org/pdf/2208.03054.
6. Chen Y, Xu L, Liu K, et al. Event extraction via dynamic multi-pooling convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. 2015: 167-176.
7. 郭鑫,高彩翔,陳千,等. 面向新冠新聞的三階段篇章級事件抽取方法[J]. 計算機工程與應用,2023, 59(3): 150-157.
8. Wang J, Han B, Wang F, et al. Document-level core events extraction based on QA[J]. Journal of Physics: Conference Series, 2022, 2171(1): 012062.
9. Li Q, Ji H, Huang L. Joint event extraction via structured prediction with global features[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. 2013: 73-82.
10. Nguyen T H, Cho K, Grishman R. Joint event extraction via recurrent neural networks[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 300-309.
11. 葛君偉,喬蒙蒙,方義秋. 基于上下文融合的文檔級事件抽取方法[J]. 計算機應用研究, 2022, 39(1): 48-53.
12. Bethard S, Martin J H. Identification of event mentions and their semantic class[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, 2006: 146-154.
13. Llorens H, Saquete E, Navarro B. TimeML events recognition and classification: learning CRF models with semantic roles[C]//Proceedings of the 23rd International Conference on Computational Linguistics. 2010: 725-733.
14. Boros E, Besancon R; Ferret O, et al. Event role extraction using domain-relevant word representations[C]//Proceedings of the Conference on Empirical Methods in Natural Language Proceeding. 2014: 1852-1857.
15. Zhang Z, Xu W, Chen Q. Joint event extraction based on skip-window convolutional neural networks[C]//Natural Language Understanding and Intelligent Applications: 5th CCF Conference on Natural Language Processing and Chinese Computing. 2016: 324-334.
16. Duan S, He R, Zhao W. Exploiting document level information to improve event detection via recurrent neural networks[C]//Proceedings of the Eighth International Joint Conference on Natural Language Processing. 2017: 352-361.
17. 薛頌東,李永豪,趙紅燕. 基于多粒度閱讀器和圖注意力網絡的文檔級事件抽取[J]. 計算機應用研究,2024, 41(8): 2329-2335.
18. 田三川. 基于問答的中文事件抽取研究[D]. 蘇州: 蘇州大學,2022.
19. 張虎,張廣軍. 基于多粒度實體異構圖的篇章級事件抽取方法[J]. 計算機科學, 2023, 50(5): 255-261.
20. 余傳明,鄧斌,談臘云,等. 基于XLNET和GAT的句法信息增強事件抽取模型[J/OL]. 數據分析與知識發現: 1-18[2024-04-30]. http://kns.cnki.net/kcms/detail/10.1478.G2.20230925.0840.002.html.
21. 蘇方方,李霏,姬東鴻. 基于可控解碼策略的生成式生物醫學事件抽取[J]. 中文信息學報,2023, 37(11): 68-80.
22. Su J, Lu Y, Pan S, et al. RoFormer: enhanced transformer with rotary position embedding[EB/OL]. [2024-05-05]. https://arxiv.org/pdf/2104.09864v4.
23. 蘇劍林. RoFormerV2: 自然語言理解的極限探索[EB/OL]. [2024-10-11]. https://kexue.fm/archives/8998.




