摘要:論文《兩階段域適應(yīng)神經(jīng)機(jī)器翻譯方法》發(fā)表在《 廈門大學(xué)學(xué)報(自然科學(xué)版) 》,版權(quán)歸《廈門大學(xué)學(xué)報(自然科學(xué)版)》所有。本文來自網(wǎng)絡(luò)平臺,僅供參考。 [目的] 為了提升神經(jīng)機(jī)器翻譯模
論文《兩階段域適應(yīng)神經(jīng)機(jī)器翻譯方法》發(fā)表在《廈門大學(xué)學(xué)報(自然科學(xué)版)》,版權(quán)歸《廈門大學(xué)學(xué)報(自然科學(xué)版)》所有。本文來自網(wǎng)絡(luò)平臺,僅供參考。
[目的] 為了提升神經(jīng)機(jī)器翻譯模型的遷移學(xué)習(xí)效果,以語言數(shù)據(jù)為中心開展域適應(yīng)方法探索。[方法] 根據(jù)KL散度和最大均差兩種域適應(yīng)量度的定量分析結(jié)果,提出一種針對擁有大規(guī)模平行句子和小規(guī)模域文本場景的兩階段減量學(xué)習(xí)框架。第1階段域過濾,利用域文本過濾平行句子,得到域平行句子,再利用得到的域平行句子訓(xùn)練出域神經(jīng)機(jī)器翻譯模型。第2階段質(zhì)量過濾,利用訓(xùn)練出的域神經(jīng)機(jī)器翻譯模型將第1階段過濾出的域平行句子翻譯一遍,比較機(jī)器譯文與人工譯文的質(zhì)量,刪除低質(zhì)量平行句子以獲得高質(zhì)量域平行句子。最后利用得到的高質(zhì)量域平行句子訓(xùn)練出優(yōu)化的域神經(jīng)機(jī)器翻譯模型。[結(jié)果] 在適應(yīng)法律域英漢神經(jīng)機(jī)器翻譯上的實(shí)驗(yàn)結(jié)果顯示,新提出的兩階段算法只需原來訓(xùn)練步的四分之一左右,反而可以提高2個多的BLEU分?jǐn)?shù)。[結(jié)論] 實(shí)驗(yàn)結(jié)論證明減量學(xué)習(xí)框架能夠在大大減少訓(xùn)練時空開銷的前提下獲得最優(yōu)的性能,最終實(shí)現(xiàn)神經(jīng)機(jī)器翻譯模型的快速域遷移。
關(guān)鍵詞
域適應(yīng);域適應(yīng)量度;減量學(xué)習(xí);神經(jīng)機(jī)器翻譯;法律域
引言
近段時間以來,基于多層神經(jīng)網(wǎng)絡(luò)的深度學(xué)習(xí)算法已經(jīng)能夠從大規(guī)模雙語平行句對數(shù)據(jù)中訓(xùn)練得到譯文質(zhì)量很高的神經(jīng)機(jī)器翻譯(neural machine translation, NMT)模型。得益于向量計算部件擁有的超級并行算力、多層神經(jīng)網(wǎng)絡(luò)捕獲的深度語義特征以及平行語言大數(shù)據(jù)蘊(yùn)含的寬背景上下文知識,富資源通用NMT得到了充分的研究,產(chǎn)生了一系列優(yōu)秀算法、數(shù)據(jù)資源和實(shí)用工具[1]。隨著語言大數(shù)據(jù)爆炸增長,富資源機(jī)器翻譯研究更加關(guān)注遷移學(xué)習(xí)(transfer learning)方法,正朝著域適應(yīng)(domain adaptation)方向邁進(jìn)。
遷移學(xué)習(xí)是一個機(jī)器學(xué)習(xí)問題。機(jī)器學(xué)習(xí)往往包含源域(source domain, Ds)和目標(biāo)域(target domain, Dt)、源任務(wù)(source task, Ts)和目標(biāo)任務(wù)(target task, Tt)兩組成對的源目概念。在描述機(jī)器學(xué)習(xí)數(shù)據(jù)時,習(xí)慣用訓(xùn)練(樣本)集和測試(樣本)集概念來對應(yīng)源域和目標(biāo)域。通常的機(jī)器學(xué)習(xí)是雙同構(gòu)的,也就是域相同(Ds=Dt)且任務(wù)相同(Ts=Tt)。而遷移學(xué)習(xí)則是異構(gòu)機(jī)器學(xué)習(xí),即域不同(Ds≠Dt)或任務(wù)不同(Ts≠Tt),亦或二者皆不同。具體而言,遷移學(xué)習(xí)致力于利用源域Ds和源任務(wù)Ts來提高目標(biāo)域Dt和目標(biāo)任務(wù)Tt的機(jī)器學(xué)習(xí)效果。
域適應(yīng)是一種特殊的遷移學(xué)習(xí),即任務(wù)相同(Ts=Tt),例如都是機(jī)器翻譯任務(wù),但域不同(Ds≠Dt),例如訓(xùn)練集是通用的廣域英漢句對,而測試集是法律域英漢句對。在描述域適應(yīng)時,還習(xí)慣用域外(out-domain)和域內(nèi)(in-domain)概念來對應(yīng)遷移學(xué)習(xí)的源域和目標(biāo)域。域適應(yīng)中的域不同可以具體表現(xiàn)為源域和目標(biāo)域的數(shù)據(jù)分布不一致,也可以表現(xiàn)為存在大量帶標(biāo)簽的域外樣本,而域內(nèi)帶標(biāo)簽的樣本沒有或者極少。
域適應(yīng)機(jī)器翻譯研究旨在探索如何利用信息豐富的域外樣本提升域內(nèi)機(jī)器翻譯模型的性能。因?yàn)橛?xùn)練集和測試集的數(shù)據(jù)分布不一致時,通常機(jī)器學(xué)習(xí)出的模型往往會過擬合源域,從而降低了在目標(biāo)域上的泛化性。眾所周知,在機(jī)器翻譯或人工翻譯將一種符號轉(zhuǎn)化成另一種符號的過程中,都會面臨域?qū)S性~表、域特有表達(dá)等域相關(guān)的問題。理想的域適應(yīng)機(jī)器翻譯能夠根據(jù)域快速得到合適的機(jī)器翻譯模型。
1 相關(guān)研究
回顧域適應(yīng)研究歷史,早在統(tǒng)計機(jī)器翻譯時期就產(chǎn)生了大量研究成果[2]。當(dāng)前,域適應(yīng)NMT研究繼承和發(fā)展了域適應(yīng)統(tǒng)計機(jī)器翻譯的兩種主要思路[3]。一是以模型為中心(model-centric)改進(jìn)神經(jīng)網(wǎng)絡(luò),通過干預(yù)神經(jīng)網(wǎng)絡(luò)的架構(gòu)、訓(xùn)練以及解碼實(shí)現(xiàn)域適應(yīng)。另一是以數(shù)據(jù)為中心(data-centric)挑選域相關(guān)的訓(xùn)練樣本,包括充分發(fā)揮域內(nèi)單語數(shù)據(jù)、域外高質(zhì)量平行數(shù)據(jù)以及未知質(zhì)量平行數(shù)據(jù)的規(guī)模優(yōu)勢等。由于以模型為中心也會使用到單語或平行數(shù)據(jù),所以上述兩種思路之間也存在交疊。
1.1 以模型為中心的研究
以模型為中心的思路注重深度學(xué)習(xí)算法的改進(jìn),代表性研究主要包括:
1. 干預(yù)神經(jīng)網(wǎng)絡(luò)架構(gòu):Tobias等[4]提出一種適用于域內(nèi)單語數(shù)據(jù)的技術(shù),即聯(lián)合訓(xùn)練域語言模型和NMT模型的深融合(deep fusion)技術(shù)。Britz等[5]提出了一種適用于多域數(shù)據(jù)的技術(shù),即在編碼器(encoder)頂部添加前饋神經(jīng)網(wǎng)絡(luò)(feedforward neural network, FNN)并利用注意力預(yù)測源句域的域判別器(discriminator)技術(shù)。Kobus等[6]提出將詞級特征(word-level features)附加到NMT的嵌入(Embedding)層來控制域并預(yù)測源句域標(biāo)簽。
2. 干預(yù)神經(jīng)網(wǎng)絡(luò)訓(xùn)練:Chen等[7]使用域分類器修改NMT代價函數(shù),將域分類器輸出概率轉(zhuǎn)化為域權(quán)重,使用驗(yàn)證數(shù)據(jù)訓(xùn)練該分類器。后續(xù)Wang等[8]提出了NMT句子選擇和加權(quán)的聯(lián)合框架。Varga[9]將微調(diào)(fine tuning)應(yīng)用于從可比語料中提取的平行數(shù)據(jù)。為防止域內(nèi)數(shù)據(jù)微調(diào)后域外退化,后續(xù)Praveen等[10]提出了一種保持域外模型分布的基于知識蒸餾的擴(kuò)展微調(diào)技術(shù)。Dou等[11]直接學(xué)習(xí)出源域和目標(biāo)域之間的差異,并利用該差異改進(jìn)模型的訓(xùn)練。Chu等[12]集成多域和微調(diào),提出一種混合微調(diào)(mixed-fine tuning)技術(shù),較好地解決了因域內(nèi)數(shù)據(jù)量小而導(dǎo)致的微調(diào)過擬合問題。此外,針對微調(diào)過程中的過擬合問題,Miceli等[13]探索了正則化(regularization)技術(shù)。
3. 干預(yù)神經(jīng)網(wǎng)絡(luò)解碼:Adams等[14]提出一種淺融合(shallow fusion)解碼算法,先在大規(guī)模單語數(shù)據(jù)上訓(xùn)練語言模型,然后結(jié)合語言模型與預(yù)訓(xùn)練的NMT模型,加權(quán)評估概率以生成下一個單詞。該算法可以用于低資源域適應(yīng)NMT。Freitag等[15]提出將域外模型和微調(diào)后的域內(nèi)模型集成解碼。Khayrallah等[16]提出了一種基于堆棧(stack-based)的詞格(word lattices)解碼算法。在域適應(yīng)實(shí)驗(yàn)中,詞格由統(tǒng)計機(jī)器翻譯生成,最終的解碼效果優(yōu)于傳統(tǒng)解碼。
1.2 以數(shù)據(jù)為中心的研究
以數(shù)據(jù)為中心的思路更加適合快速實(shí)現(xiàn)工程應(yīng)用,代表性研究主要包括:
1. 利用域內(nèi)單語數(shù)據(jù):域內(nèi)單語數(shù)據(jù)不易直接用于NMT的語言模型,Currey等[17]將目標(biāo)域單語數(shù)據(jù)復(fù)制到源域,并使用復(fù)制的數(shù)據(jù)訓(xùn)練NMT。Zhang等[18]使用雙語詞典和單語數(shù)據(jù)通過預(yù)測翻譯和句子排序多任務(wù)學(xué)習(xí)來加強(qiáng)NMT編碼器。Cheng等[19]利用NMT作為自編碼器對單語數(shù)據(jù)進(jìn)行重構(gòu),將源域單語數(shù)據(jù)和目標(biāo)域單語數(shù)據(jù)同時用于NMT。
2. 利用域外高質(zhì)量平行數(shù)據(jù):通過利用大規(guī)模高質(zhì)量平行數(shù)據(jù)訓(xùn)練得到通用機(jī)器翻譯模型,再遷移到特定目標(biāo)域。相關(guān)研究與以模型為中心的干預(yù)神經(jīng)網(wǎng)絡(luò)訓(xùn)練研究中微調(diào)、混合微調(diào)有交疊。Wang等[20]將統(tǒng)計機(jī)器翻譯中的數(shù)據(jù)選擇(data selection)思想用于NMT,根據(jù)句子嵌入相似性(sentence embedding similarity)從域外數(shù)據(jù)中選擇接近域內(nèi)數(shù)據(jù)的句子。Van Der Wees等[21]提出了一種動態(tài)數(shù)據(jù)選擇方法,在NMT的不同訓(xùn)練階段采用不同的訓(xùn)練樣本集。
3. 利用未知質(zhì)量平行數(shù)據(jù):對于互聯(lián)網(wǎng)上的富資源語言,比較容易獲得大規(guī)模平行句子。這些包含多域的平行句子混在一起反而與某個具體域關(guān)聯(lián)度不顯著,更有甚者還有可能包含錯誤[22]。對同時針對某個具體域的情況,Hu等[23]已經(jīng)擁有一定規(guī)模的單語或雙語域詞集、域文本文檔等資源。劉歡等[24]從多域的平行句子中挑選高質(zhì)量旅游域平行句子進(jìn)行數(shù)據(jù)增強(qiáng)。上述場景比較接近真實(shí)應(yīng)用中的數(shù)據(jù)環(huán)境,如何利用這類未知質(zhì)量的平行數(shù)據(jù),實(shí)現(xiàn)適應(yīng)具體域的NMT是一個更具體、更實(shí)用的研究問題。圍繞該研究問題,我們定量分析了兩種域適應(yīng)量度,嘗試提出一種兩階段減量學(xué)習(xí)新思路。
2 域適應(yīng)量度
為了定量計算源域與目標(biāo)域之間的適應(yīng)程度,首先計算源域數(shù)據(jù)詞表Vs和目標(biāo)域數(shù)據(jù)詞表Vt的并集(V={v_{1}, v_{2}, cdots, v_{n}}),接著根據(jù)n維向量基V分別統(tǒng)計得到源域數(shù)據(jù)的詞頻向量(S={s_{1}, s_{2}, cdots, s_{n}})和目標(biāo)域數(shù)據(jù)的詞頻向量(T={t_{1}, t_{2}, cdots, t_{n}}),最后采用統(tǒng)計學(xué)上的KL散度(kullback-leibler divergence, KLD)和最大均差(maximum mean discrepancy, MMD)來衡量源域與目標(biāo)域的差異程度。
2.1 KL散度
兩個詞頻向量S與T的散度公式如下:
2.2 最大均差
兩個詞頻向量S與T的最大均差公式(采用高斯核函數(shù)(k(x, y))改寫后的可計算版本)如下:
最大均差是遷移學(xué)習(xí)尤其是域適應(yīng)算法中使用最廣泛的一種損失函數(shù),主要用來度量兩個不同但相關(guān)的分布之間的距離[26]。
2.3 量度分析
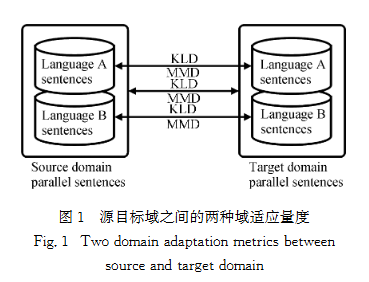
由于遷移學(xué)習(xí)任務(wù)是機(jī)器翻譯,因此還存在兩對源目標(biāo)概念。如圖1所示,源域和目標(biāo)域的數(shù)據(jù)都是平行句對,而根據(jù)機(jī)器翻譯方向,源語言是A而目標(biāo)語言是B。分別統(tǒng)計出源域A語言句對與目標(biāo)域A語言句對之間的KLD和MMD、源域B語言句對與目標(biāo)域B語言句對之間的KLD和MMD以及源域平行句對與目標(biāo)域平行句對之間的KLD和MMD。
對已有的3組英漢平行句子語料進(jìn)行了統(tǒng)計分析。其中LAW07語料包含源域21942400句對,LAW08語料包含源域5899520句對,LAW09語料包含源域5710080句對,這3組語料都包含完全相同的目標(biāo)域50000句對。得到英漢語料域適應(yīng)量度數(shù)值如表1所示(表中數(shù)值為乘以(10^6)后的結(jié)果)。
表1 英漢語料域適應(yīng)量度
| 源語料(句對數(shù)) | 目標(biāo)語料(句對數(shù)) | KLD×10? | MMD×10? |
| LAW07.train.eng(21942400) | LAW07.test.eng(50000) | 11.028 | 21.935 |
| LAW08.train.eng(5899520) | LAW08.test.eng(50000) | 1.144 | 4.292 |
| LAW09.train.eng(5710080) | LAW09.test.eng(50000) | 1.098 | 2.384 |
| LAW07.train.zho(21942400) | LAW07.test.zho(50000) | 93.858 | 262.260 |
| LAW08.train.zho(5899520) | LAW08.test.zho(50000) | 9.254 | 99.182 |
| LAW09.train.zho(5710080) | LAW09.test.zho(50000) | 8.911 | 69.141 |
| LAW07.train.engzho(43884800) | LAW07.test.engzho(100000) | 41.145 | 30.041 |
| LAW08.train.engzho(11799040) | LAW08.test.engzho(100000) | 4.695 | 20.027 |
| LAW09.train.engzho(11420160) | LAW09.test.engzho(100000) | 4.297 | 19.550 |
表1中的數(shù)值表明,無論從英語、漢語各自單語視角還是從英漢雙語視角看,LAW09語料源域和目標(biāo)域更加接近。分析表1數(shù)值可知,語料規(guī)模越大,域適應(yīng)性不一定更強(qiáng),規(guī)模最大的LAW07語料域適應(yīng)性最差,規(guī)模最小的LAW09語料域適應(yīng)性最好。
3 減量學(xué)習(xí)
在上一節(jié)域適應(yīng)量度統(tǒng)計分析結(jié)果的啟發(fā)下,探索一種工程級減量學(xué)習(xí)新思路,以數(shù)據(jù)為中心,充分發(fā)揮未知質(zhì)量平行數(shù)據(jù)的規(guī)模優(yōu)勢,實(shí)現(xiàn)高效域NMT。
3.1 框架
減量學(xué)習(xí)框架如圖2所示,主要包括域過濾器(domain filter)、質(zhì)量過濾器(quality filter)以及3個相同的NMT訓(xùn)練器(NMT trainer)。執(zhí)行該框架的前置數(shù)據(jù)包括通用平行句子(common parallel sentences)和域文本資源(domain text resources)。其中,通用平行句子是指大規(guī)模、易獲得、域不明確(也可能是多域相關(guān))、可能包含錯誤的雙語數(shù)據(jù);而域文本資源可以是單語或雙語數(shù)據(jù),例如域詞集、域文本文檔等。
上述減量學(xué)習(xí)框架是一種獨(dú)立于具體的過濾算法、機(jī)器翻譯算法、源語言目標(biāo)語言的元框架。以法律域英漢機(jī)器翻譯為例,描述減量學(xué)習(xí)框架的執(zhí)行過程:
1. 第1階段減量學(xué)習(xí):域過濾器根據(jù)域文本資源對通用平行句子中的每對句子進(jìn)行屬于法律域和不屬于法律域的二值分類,最終過濾得到域平行句子(domain parallel sentences)。接著利用NMT訓(xùn)練器分別在通用平行句子和域平行句子上訓(xùn)練得到通用英漢NMT模型和法律域英漢NMT模型。
2. 第2階段減量學(xué)習(xí):先采用法律域英漢NMT模型翻譯域平行句子中的每個英語句子,接著在質(zhì)量過濾器中調(diào)用萊文斯坦(levenshtein)字符串距離函數(shù),計算原有漢語句子與機(jī)器翻譯輸出的漢語句子之間的相似度,根據(jù)預(yù)設(shè)閾值過濾掉相似度較低的句對,最終得到高質(zhì)量域平行句子(high quality domain parallel sentences)并再次訓(xùn)練得到優(yōu)化的法律域英漢NMT模型。此處預(yù)設(shè)閾值為0.9,以保證過濾的嚴(yán)格性。
整個框架能夠訓(xùn)練出3個英漢NMT模型,其中通用英漢NMT模型僅用于實(shí)驗(yàn)對比參照。
3.2 算法
圍繞實(shí)際的域適應(yīng)NMT需求,根據(jù)減量學(xué)習(xí)框架設(shè)計了兩階段減量學(xué)習(xí)NMT算法,具體流程如圖3所示。
算法說明:
輸入:初始訓(xùn)練集(train,通用平行句子)、開發(fā)集(dev,域平行句子)、測試集(test,域平行句子)、域文本資源(dtr)。
輸出:優(yōu)化的域NMT模型(odnmt)。
核心步驟:
1. 第7行:訓(xùn)練通用NMT模型(cnmt),僅用于對比。
2. 第8行:通過域過濾器(DomainFilter.filter)從通用平行句子中篩選出域平行句子(train)。
3. 第9行:利用域平行句子訓(xùn)練域NMT模型(dnmt)。
4. 第11-14行:使用域NMT模型翻譯域平行句子中的源語言句子,得到機(jī)器譯文(mtout)。
5. 第15行:通過質(zhì)量過濾器(QualityFilter.filter)對比機(jī)器譯文與人工譯文,篩選出高質(zhì)量域平行句子(train)。
6. 第16行:利用高質(zhì)量域平行句子訓(xùn)練優(yōu)化的域NMT模型(odnmt)。
關(guān)鍵實(shí)現(xiàn):
NMT訓(xùn)練器(NMTTrainer.train):采用基于注意力機(jī)制的編碼器-解碼器實(shí)現(xiàn)①。
域過濾函數(shù)(DomainFilter.filter):采用基于字符串-頻率索引(string-frequency index, SFI)的文本分類(SFITC)算法實(shí)現(xiàn)[27],適合短文本過濾,時空效率高。
質(zhì)量過濾函數(shù)(QualityFilter.filter):采用集成機(jī)器翻譯過濾算法實(shí)現(xiàn)[28],調(diào)用萊文斯坦字符串距離函數(shù)計算句子相似度,工程實(shí)現(xiàn)簡單。
4 實(shí)驗(yàn)
為了驗(yàn)證減量學(xué)習(xí)的有效性與高效性,進(jìn)行了法律域英漢NMT實(shí)驗(yàn)。
4.1 實(shí)驗(yàn)環(huán)境與數(shù)據(jù)
4.1.1 示范驗(yàn)證系統(tǒng)
根據(jù)減量學(xué)習(xí)框架實(shí)現(xiàn)了兩階段減量學(xué)習(xí)NMT算法,集成的基于注意力機(jī)制的編碼器-解碼器超參數(shù)如下:神經(jīng)元數(shù)(num_units=512)、編碼器/解碼器層數(shù)(num_encoder_layers=num_decoder_layers=4)、訓(xùn)練輪數(shù)(epoch=10)、批量規(guī)模(batch_size=128)、束搜索寬度(beam_width=10),其他參數(shù)保持缺省值。最終增加交互界面實(shí)現(xiàn)Web服務(wù)器,通過互聯(lián)網(wǎng)發(fā)布英漢NMT應(yīng)用①。
4.1.2 實(shí)驗(yàn)數(shù)據(jù)制備
域過濾器構(gòu)建:抓取英語法律詞匯76792條,構(gòu)建法律域雙語詞集;抓取漢英法律文本及學(xué)術(shù)論文,得到1346519條法律域雙語句集;抓取其他域?qū)W術(shù)論文,構(gòu)建2850764條其他域雙語句集。
平行句庫:人工構(gòu)建100000對英漢法律域平行句子,等分為開發(fā)集(50000句對)和測試集(50000句對)。
訓(xùn)練集:收集整理21942400對英漢平行句子(LAW07語料)作為初始訓(xùn)練集,經(jīng)兩階段減量學(xué)習(xí)后得到LAW08語料(5899520句對)和LAW09語料(5710080句對)。
預(yù)處理:漢語句子處理為空格分割的單字,英語句子處理為空格分割的小寫單詞。
4.2 實(shí)驗(yàn)結(jié)果與分析
4.2.1 基礎(chǔ)實(shí)驗(yàn)結(jié)果
英漢NMT實(shí)驗(yàn)結(jié)果如表2所示,采用BLEU(BLEU4)、chrF2、TER三個指標(biāo)評價模型性能(BLEU和chrF2數(shù)值越大越好,TER數(shù)值越小越好)。
表2 英漢NMT模型結(jié)果
| 語料 | 訓(xùn)練集句對數(shù) | 訓(xùn)練集詞表規(guī)模 | 訓(xùn)練集Token數(shù) | 訓(xùn)練步數(shù) | BLEU | chrF2 | TER |
| LAW07 | 21942400 | 326515 | 479825064 | 1714250 | 45.41 | 38.62 | 40.21 |
| LAW08 | 5899520 | 157432 | 136738636 | 460900 | 47.13 | 40.14 | 40.13 |
| LAW09 | 5710080 | 152340 | 133156728 | 446100 | 47.88 | 40.77 | 38.99 |
結(jié)果分析:
兩階段減量學(xué)習(xí)減少了訓(xùn)練語料規(guī)模,但模型性能持續(xù)提升,LAW09語料訓(xùn)練的模型各項(xiàng)指標(biāo)最優(yōu)。
訓(xùn)練步數(shù)大幅減少,LAW09的訓(xùn)練步數(shù)僅為LAW07的四分之一左右,驗(yàn)證了減量學(xué)習(xí)的高效性。
4.2.2 學(xué)習(xí)曲線分析
英漢NMT實(shí)驗(yàn)的3個NMT模型訓(xùn)練過程中的學(xué)習(xí)曲線如圖5所示(橫坐標(biāo)為訓(xùn)練步,縱坐標(biāo)為BLEU)。
結(jié)果分析:訓(xùn)練步最少的LAW09模型BLEU值最高,說明減量學(xué)習(xí)能夠在減少訓(xùn)練開銷的同時,獲得更優(yōu)的模型性能。
4.2.3 BPE預(yù)處理實(shí)驗(yàn)
采用BPE(byte pair encoding)子詞切分工具①對3組語料中的英語句子進(jìn)行32k詞表預(yù)處理后,重新訓(xùn)練NMT模型,實(shí)驗(yàn)結(jié)果如表3所示。
表3 基于BPE的英漢NMT模型結(jié)果
| 語料 | 訓(xùn)練集句對數(shù) | 訓(xùn)練集詞表規(guī)模 | 訓(xùn)練集Token數(shù) | 訓(xùn)練步數(shù) | BLEU | chrF2 | TER |
| LAW07.BPE | 21942400 | 32134 | 490060812 | 1714250 | 46.75 | 39.36 | 39.08 |
| LAW08.BPE | 5899520 | 32033 | 139420536 | 460900 | 48.02 | 40.73 | 39.34 |
| LAW09.BPE | 5710080 | 32018 | 135699728 | 446100 | 48.69 | 41.24 | 38.25 |
結(jié)果分析:
BPE預(yù)處理壓縮了詞表規(guī)模,有效處理未登錄詞問題,所有模型性能均有所提升。
兩階段減量學(xué)習(xí)框架對采用BPE預(yù)處理的模型依然有效,LAW09.BPE模型性能最優(yōu),驗(yàn)證了框架的通用性。
4.3 實(shí)驗(yàn)結(jié)論
綜合域適應(yīng)量度統(tǒng)計結(jié)果與法律域英漢NMT實(shí)驗(yàn)結(jié)果,得出以下結(jié)論:
1. 法律域英漢NMT模型的BLEU評分排序與語料的KLD和MMD數(shù)值排序完全吻合,驗(yàn)證了KL散度和最大均差能夠有效定量度量域適應(yīng)NMT中源域與目標(biāo)域語料的適應(yīng)程度。
2. 減量學(xué)習(xí)是有效的域適應(yīng)策略:域過濾增強(qiáng)了訓(xùn)練語料的域適應(yīng)性,質(zhì)量過濾提高了訓(xùn)練語料的域相關(guān)譯文質(zhì)量。
3. 兩階段減量學(xué)習(xí)NMT算法只需原來訓(xùn)練步的四分之一左右,即可提高2個多的BLEU點(diǎn),驗(yàn)證了減量學(xué)習(xí)框架能夠高效達(dá)到最優(yōu)NMT性能。
4. 對于域NMT模型訓(xùn)練,關(guān)鍵在于高質(zhì)量域相關(guān)語料,而非單純追求語料規(guī)模,減量學(xué)習(xí)為從大規(guī)模未知質(zhì)量語料到高質(zhì)量域相關(guān)語料的數(shù)據(jù)工程提供了有益嘗試。
5 結(jié)論
圍繞域適應(yīng)NMT問題,采用以數(shù)據(jù)為中心的思路,充分發(fā)揮未知質(zhì)量平行數(shù)據(jù)的規(guī)模優(yōu)勢,通過域過濾和質(zhì)量過濾兩階段提高平行數(shù)據(jù)的域關(guān)聯(lián)度和譯文質(zhì)量。最終在減量學(xué)習(xí)元框架下集成基于注意力機(jī)制的編碼器-解碼器用以實(shí)現(xiàn)NMT訓(xùn)練器,并在法律域英漢機(jī)器翻譯實(shí)驗(yàn)中驗(yàn)證了所提減量學(xué)習(xí)的效果。
下一步研究主要關(guān)注域知識建模和域知識干預(yù)NMT模型研究:準(zhǔn)備構(gòu)建顯式的多語言域知識圖譜,增強(qiáng)跨語言復(fù)雜域知識的神經(jīng)可計算性,進(jìn)一步提升域適應(yīng)NMT的譯文質(zhì)量;在減量學(xué)習(xí)元框架中試驗(yàn)語義過濾和形態(tài)語義集成過濾等更具性能潛力的算法,并將相關(guān)研究成果遷移到其他適合的域NMT應(yīng)用當(dāng)中。
參考文獻(xiàn)
[1] TAN Z X, WANG S, YANG Z H, et al. Neural machine translation: a review of methods, resources, and tools[J]. AI Open, 2020, 1: 5-21.
[2] 崔磊, 周明. 統(tǒng)計機(jī)器翻譯領(lǐng)域自適應(yīng)綜述[J]. 智能計算機(jī)與應(yīng)用, 2014, 4(6): 31-34.
[3] CHU C H, WANG R. A survey of domain adaptation for neural machine translation[C]∥Proceedings of the 27th International Conference on Computational Linguistics. [S. l.]: ICCL, 2018: 1304-1319.
[4] TOBIAS D, FELIX H. Using target-side monolingual data for neural machine translation through multi-task learning[C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. [S. l.]: EMNLP, 2013: 1500-1505.
[5] BRITZ D, LE Q, PRYZANT R. Effective domain mixing for neural machine translation[C]∥Proceedings of the Second Conference on Machine Translation. Copenhagen: Association for Computational Linguistics, 2017: 118-126.
[6] KOBUS C, CREGO J, SENELLART J. Domain control for neural machine translation[C]∥Proceedings of the International Conference Recent Advances in Natural Language Processing. [S. l.]: ICRANLP, 2016: 372-378.
[7] CHEN B X, CHERRY C, FOSTER G, et al. Cost weighting for neural machine translation domain adaptation[C]∥Proceedings of the First Workshop on Neural Machine Translation. Vancouver: Association for Computational Linguistics, 2017: 40-46.
[8] WANG R, UTIYAMA M, FINCH A, et al. Sentence selection and weighting for neural machine translation domain adaptation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(10): 1727-1741.
[9] VARGA Á. Domain adaptation for multilingual neural machine translation[C]∥Computer Science, Linguistics. [S. l.]: CSL, 2017: 64478408.
[10] PRAVEEN D, CHRISTOF M. Fine-tuning for neural machine translation with limited degradation across in-and out-of-domain data[C]∥Proceedings of the 16th Machine Translation Summit. [S. l.]: MTS, 2017: 156-169.
[11] DOU Z Y, WANG X Y, HU J J, et al. Domain differential adaptation for neural machine translation[C]∥Proceedings of the 3rd Workshop on Neural Generation and Translation. Hong Kong: Association for Computational Linguistics, 2019: 59-69.
[12] CHU C H, DABRE R AJ, SADAO K. An empirical comparison of domain adaptation methods for neural machine translation[C]∥Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: Association for Computational Linguistics, 2017: 385-391.
[13] MICELI B A V, HADDOW B, GERMANN U, et al. Regularization techniques for fine-tuning in neural machine translation[C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics, 2017: 1489-1494.
[14] ADAMS V, SUBRAMANIAN S, CHRZANOWSKI M, et al. Finding the right recipe for low resource domain adaptation in neural machine translation[EB/OL]. (2022-01-02)[2023-12-01]. http:∥arxiv.org/abs/2206.01137.
[15] FREITAG M, AL-ONAIZAN Y. Fast domain adaptation for neural machine translation[EB/OL]. (2016-12-20)[2023-12-01]. http:∥arxiv.org/abs/1612.06897.
[16] KHAYRALLAH H, KUMAR M, DU H, et al. Neural lattice search for domain adaptation in machine translation[C]∥Proceedings of the Eighth International Joint Conference on Natural Language Processing. Taipei: AFNLP, 2017: 20-25.
[17] CURREY A, MICELI BARONE A V, HEAFIELD K. Copied monolingual data improves low-resource neural machine translation[C]∥Proceedings of the Second Conference on Machine Translation. Copenhagen: Association for Computational Linguistics, 2017: 148-156.
[18] ZHANG J J, ZONG C Q. Bridging neural machine translation and bilingual dictionaries[EB/OL]. (2016-10-24)[2023-12-01]. http:∥arxiv.org/abs/1610.07272.
[19] CHENG Y, XU W, HE Z J, et al. Semi-supervised learning for neural machine translation[C]∥Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: Association for Computational Linguistics, 2016: 1965-1974.
[20] WANG R, FINCH A, UTIYAMA M, et al. Sentence embedding for neural machine translation domain adaptation[C]∥Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: Association for Computational Linguistics, 2017: 560-566.
[21] VAN DER WEES M, BISAZZA A, MONZ C. Dynamic data selection for neural machine translation[C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics, 2017: 1400-1410.
[22] SAUNDERS D. Domain adaptation and multi-domain adaptation for neural machine translation: a survey[EB/OL]. (2021-04-14)[2023-12-01]. http:∥arxiv.org/abs/2104.06951.
[23] HU J J, XIA M Z, NEUBIG G, et al. Domain adaptation of neural machine translation by lexicon induction[C]∥Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: Association for Computational Linguistics, 2019: 2989-3001.
[24] 劉歡, 劉俊鵬, 黃鍇宇, 等. 面向低資源俄漢機(jī)器翻譯的領(lǐng)域適應(yīng)方法[J]. 廈門大學(xué)學(xué)報(自然科學(xué)版), 2022, 61(4): 654-659.
[25] TUAN NGUYEN A, TOAN T, YARIN G, et al. KL guided domain adaptation[EB/OL]. (2021-01-14)[2023-12-01]. https:∥arxiv.org/abs/2106.07780v2.
[26] WANG W, LI H J, DING Z M, et al. Rethink maximum mean discrepancy for domain adaptation[EB/OL]. (2020-07-01)[2023-12-01]. http:∥arxiv.org/abs/2007.00689.
[27] LIU W Y, WANG L, YIM Z, et al. Active multi-field learning for spam filtering[J]. Comput Informatics, 2015, 33: 1400-1427.
[28] LIU W Y, WANG L. Ensemble machine translation to filter low quality corpus[C]∥2022 International Conference on Asian Language Processing (IALP). Singapore: IEEE, 2022: 500-504.
[29] 劉伍穎, 王挺. 結(jié)構(gòu)化集成學(xué)習(xí)垃圾郵件過濾[J]. 計算機(jī)研究與發(fā)展, 2012, 49(3): 628-635.
[30] POPOVI? M. chrF: character n-gram F-score for automatic MT evaluation[C]∥Proceedings of the Tenth Workshop on Statistical Machine Translation. Lisbon: Association for Computational Linguistics, 2015: 392-395.
[31] POST M. A call for clarity in reporting BLEU scores[C]∥Proceedings of the Third Conference on Machine Translation: Research Papers. Brussels: Association for Computational Linguistics, 2018: 186-191.
[32] SENNRICH R, HADDOW B, BIRCH A. Neural machine translation of rare words with subword units[C]∥Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: Association for Computational Linguistics, 2016: 1715-1725.




