摘要:摘要:在高比例新能源接入下,配置儲能可以輔助電力系統削峰填谷,平抑波動。然而目前儲能系統成本較高,需要政府進行支持。為此,提出了一種儲能盈利策略,以在電網、儲能運營商和
摘要:在高比例新能源接入下,配置儲能可以輔助電力系統削峰填谷,平抑波動。然而目前儲能系統成本較高,需要政府進行支持。為此,提出了一種儲能盈利策略,以在電網、儲能運營商和用戶組成的電力市場中實現運營利潤最大化。結合智能算法提出了一種考慮激勵的盈利策略,為每個峰值時段的儲能系統運營商提供不同權重的獎勵分配。該算法一方面基于最小二乘支持向量機的深度學習,來建立價格和負荷預測模型;另一方面基于深度強化學習,考慮電網的峰值狀態、用戶負荷需求和儲能系統運營商利潤,確定最優充放電策略。最后通過案例分析,驗證該策略可以顯著提高儲能系統運營商利潤并減輕電網壓力。
關鍵詞:儲能系統;盈利策略;支持向量機;深度強化學習算法
論文《基于深度強化學習算法的儲能系統盈利策略研究》發表在《電力需求側管理》,版權歸《電力需求側管理》所有。本文來自網絡平臺,僅供參考。
0 引言
新能源的廣泛接入不斷推動著我國能源向著清潔、低碳、可持續的方向發展。但風能、太陽能等新能源的波動性會導致并網后電網的電能質量不穩定,因此在我國出現大量的棄風棄光現象。
儲能是我國能源主管部門非常認可的一種提高新能源利用效率和供電可靠水平的技術手段。由于儲能成本高,需要結合電網運行控制要求,綜合考慮各種因素,在系統建設過程中,結合經濟投資限制、技術可靠性限制等因素對儲能系統的盈利模式進行優化,最終確定合理的儲能盈利策略。
文獻[1-2]闡述了儲能系統中的套利是一種通過在電價低時購買電力,在電價高時出售電力來追求利潤的方法。文獻[3-4]闡述了在傳統電網中,儲能主要用于可再生能源的負荷轉移、調頻和調峰。文獻[5]闡述了在智能電網采用基于激勵的需求響應的情況下,通過向用戶支付激勵來控制能源需求,將電網運營商的電力供應從高峰時段轉移到非高峰時段。該激勵綜合套利策略通過轉移電網的峰值負載,從而為儲能系統運營商帶來額外的利潤。文獻[6]應用強化學習來優化儲能系統運營商的實時套利策略,該策略通過在不同價格場景下重復執行充電和放電操作來訓練系統。
傳統的基于模型[7]的方法受到未來不確定性和最優性的限制,這也直接影響了能源套利利潤。數學模型難以預測未來電價和負荷需求,加上由于儲能系統盈利實際環境的非平穩特性,儲能系統運行的不確定性導致現有盈利策略無法保證盈利最優。
為更好地進行策略的應用,本文首先應用最小二乘支持向量機預測負荷和價格,其次考慮電網峰值狀態、儲能系統運營商利潤和電網負荷需求,應用深度強化學習方法確定儲能系統充電或放電的最優控制策略,實現儲能系統運營商的利潤最大化。
1 模型構建
本文提出的基于人工智能的儲能系統盈利策略模型主要由電網、儲能系統、用戶3部分組成。對儲能系統運營商來說,在電價低的時候系統進行充電,在電價高的時候進行放電,把電出售給用戶。
1.1 儲能系統運行模型
式(1)表示儲能系統運營商通過交易能源資源在h時的套利收益:
R_h^{ ext{arbitrage}}=sum_{t=0}^{t_{max}}-p_tleft(frac{P_t^{ ext{cha}}}{eta^{ ext{cha}}}+P_t^{ ext{dis}}eta^{ ext{dis}}
ight) quad (1)
式中:tin{1,2,dots,t_{max}} 為要考慮的時間指標,t_{max} 為最后考慮的時間(即如果要考慮的數據為一天,則t_{max}=23);p_t 為時間段t時每單位電量的電價;P_t^{ ext{cha}}、P_t^{ ext{dis}} 分別為在每個時間步驟t從電網購買的電量和出售給用戶的電量;eta^{ ext{cha}} 與 eta^{ ext{dis}} 分別為儲能系統充放電效率。
由于充電過程中考慮到充電損耗,需要購買更多。另外,充電和放電不能在每個時間步同時發生。如果某一時間步沒有充放電量,則充放電量設置為0。
在確定每個時間段的充放電功率時,必須考慮儲能系統的電荷狀態(state of charge, SOC)來維持儲能的耐久性[8]。時間段t處的SOC由上一時間段t-1的SOC值和充放電功率大小決定,如式(2)所示,常數C^{ ext{ESS}} 為儲能系統的總容量。式(3)為SOC的范圍,S_{ ext{OC_min}} 和 S_{ ext{OC_max}} 分別為SOC的上下限。如果S_{ ext{OC_t}} 偏離這些邊界,則會對儲能的持久性產生不利影響,因此儲能操作必須在此范圍內:
S_{ ext{OC_t}}=S_{ ext{OC_{t-1}}}+frac{1}{C^{ ext{ESS}}}left(P_t^{ ext{cha}}eta^{ ext{cha}}-frac{P_t^{ ext{dis}}}{eta^{ ext{dis}}}
ight) quad (2)
S_{ ext{OC_min}} < S_{ ext{OC_t}} < S_{ ext{OC_max}} quad (3)
1.2 激勵
本文中的“激勵”[9]定義為:激勵因子varphi_t 乘以每小時的電力套利利潤所得的值。式(4)表示考慮了激勵因子varphi_t 的激勵收益。式(5)將激勵因子varphi_t 定義為彈性xi_t 的函數,如下所示:
R_h^{ ext{stimul}}=sum_{t=0}^{t_{max}}-varphi_t p_tleft(frac{P_t^{ ext{cha}}}{eta^{ ext{cha}}}+P_t^{ ext{dis}}eta^{ ext{dis}}
ight) quad (4)
varphi_t = 1 - xi_t quad (5)
1.3 成本
儲能系統在運行期間由于充放電會產生運營成本和回收成本[10]。系統運營維護成本如式(6)所示,儲電成本如式(7)所示:
C_{ ext{yw}} = C_{ ext{rg}} + C_{ ext{cd}} quad (6)
C_{ ext{cd}} = P Q quad (7)
式中:C_{ ext{yw}} 為儲能系統運營維護成本;C_{ ext{rg}} 為人工成本;C_{ ext{cd}} 為儲電成本;P為儲電價格;Q為儲電量。人工成本主要為儲能系統維護工人的工資、福利以及相應補貼等。
回收成本C_{ ext{hs}} 可表示為式(8):
C_{ ext{hs}} = lambda C_{ ext{gm}} quad (8)
式中:C_{ ext{hs}} 為儲能系統的回收成本;lambda 為回收系數;C_{ ext{gm}} 為儲能系統的購置成本。
總成本C_{ ext{all}} 表示儲能系統總成本,表示為式(9):
C_{ ext{all}} = C_{ ext{yw}} + C_{ ext{hs}} quad (9)
1.4 目標函數
因此該模型的目標是同時考慮套利收益R_h^{ ext{arbitrage}}、激勵收益R_h^{ ext{stimul}}和總成本,通過最優功率交易實現利潤最大化,如式(10)所示。為了確認激勵的效果,對有和沒有激勵收益R_h^{ ext{stimul}}的情況進行了對比研究:
maxleft(R_h^{ ext{arbitrage}} + R_h^{ ext{stimul}}
ight) - C_{ ext{all}} quad (10)
式中:R_h^{ ext{arbitrage}} 為儲能系統運營商的套利收益;R_h^{ ext{stimul}} 為儲能系統運營商的激勵收益。
2 儲能系統功率優化模型
2.1 決策過程
(1) 狀態公式:環境狀態設置為每個時間段的電價和SOC,如式(11)所示,p_t 是每個時間段的預測電價t,它將被代入第四步,S_{ ext{OC_t}} 是每個時間段儲能系統的SOC值,它將影響儲能系統運營商的行動。
s_t = left[p_t, S_{ ext{OC_t}}
ight] quad (11)
(2) 行動制定:儲能系統的行為式(12)所示,它表示儲能系統的充放電功率。這一行為范圍處在最大放電功率P^{ ext{dis}} 和最大充電功率P^{ ext{cha}} 之間,如式(13)所示。該行為放電時為負值,充電時正值,空載時為0。P^{ ext{dis, max}} 和 P^{ ext{cha, max}} 的值取決于儲能系統的值取決于儲能系統的設計條件:
a_t = left[p_t
ight] quad (12)
a_t in left[P^{ ext{dis, max}}, P^{ ext{cha, max}}
ight] quad (13)
(3) 為了在充電和放電期間保持儲能系統的耐用性,儲能系統運營商在采取行動后的下一個時間步驟(t+1)中獲得的即時獎勵r_{t+1} 如式(14)所示:
r_{t+1} = r_{t+1}^{ ext{arbitrage}} + r_{t+1}^{ ext{stimul}} + r_{t+1}^{ ext{SOC}} quad (14)
式中:r_{t+1}^{ ext{arbitrage}} 為通過充電和放電之間的價格差異獲得的套利獎勵;r_{t+1}^{ ext{stimul}} 為來自電網的激勵獎勵;r_{t+1}^{ ext{SOC}} 為與SOC狀態相關的獎勵,該狀態受到在環境中執行行動的儲能系統運營商的影響。
套利獎勵r_{t+1}^{ ext{arbitrage}} 和激勵獎勵r_{t+1}^{ ext{stimul}} 定義為式(15)和式(16)。與SOC狀態相關的獎勵r_{t+1}^{ ext{SOC}} 定義為式(17),其中r_{t+1}^{ ext{SOC}} 表示為:當SOC在邊界范圍內時,提供獎勵系數F^{ ext{reward}},當SOC超出邊界范圍時,施加懲罰系數F^{ ext{penalty}}。隨著F^{ ext{penalty}} 加大,SOC會逐漸回到邊界中。在本研究中,F^{ ext{reward}} 設置為0,F^{ ext{penalty}} 設置為-50000。
r_{t+1}^{ ext{arbitrage}} = -p_tleft(frac{P_t^{ ext{cha}}}{eta^{ ext{cha}}} + P_t^{ ext{dis}}eta^{ ext{dis}}
ight) quad (15)
r_{t+1}^{ ext{stimul}} = -varphi_t p_tleft(frac{P_t^{ ext{cha}}}{eta^{ ext{cha}}} + P_t^{ ext{dis}}eta^{ ext{dis}}
ight) quad (16)
r_{t+1}^{ ext{SOC}} = �egin{cases} F^{ ext{reward}} & (S_{ ext{OC_min}} < S_{ ext{OC_t}} < S_{ ext{OC_max}}) \ F^{ ext{penalty}} & (S_{ ext{OC_t}} leqslant S_{ ext{OC_min}} ext{ or } S_{ ext{OC_t}} geqslant S_{ ext{OC_max}}) end{cases} quad (17)
2.2 Q-學習算法
Q-學習算法[11]通過對函數Q(s_t, a_t) 進行估計來求得最優策略。其中Q(s_t, a_t) 是當前狀態s_t 下,執行動作a_t 獲得的累計回報值。
式(18)定義的Q函數是運營商在狀態s_t 執行行動時未來的預期總回報,其中E表示期望。最優策略表示為式(19):
Q(s_t, a_t) = Eleft[G_t mid s_t, a_t
ight] quad (18)
pi^*(s) = underset{a}{operatorname{argmax}} Q(s, a) quad (19)
式中:pi^*(s) 為狀態s中的最佳策略。
最優策略pi^(s) 的Q函數Q^{pi^}(s_t, a_t) 可以用式(20)中的最優方程表示,A_{t+1} 是在t+1時刻可以執行的一系列動作:
Q^{pi^}(s_t, a_t) = Eleft[r_{t+1} + gamma max_{a_{t+1} in A_{t+1}} Q^{pi^}(s_{t+1}, a_{t+1}) mid s_t, a_t
ight] quad (20)
式中:gamma in [0,1] 為折現因子,將未來的獎勵轉化為當前的獎勵的因子。在本研究中,應用式(21)所示的Q學習方法,基于狀態-動作轉換(s_{t+1}, a_{t+1}) 更新Q函數,并找到最優策略,如式(21)所示:
Q(s_t, a_t) leftarrow Q(s_t, a_t) + alphaleft[r_{t+1} + gamma max_{a_{t+1} in A_{t+1}} Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t)
ight] quad (21)
式中:alpha in [0,1] 為學習速率,它決定了估計結果的反映程度。
3 價格和負荷預測模型
3.1 模型構建
本節的數據量較小,但各影響因素與負荷之間的關系復雜,因此,利用最小二乘支持向量機[12]可以實現更好的預測效果。其主要原理如下。
對于一個樣本的集合:S=(x_i, y_i)_{i=1}^L, x_i in X in R^n 表示輸入向量,y_i in R 表示樣本輸出值,學習機可表示為如下決策函數,如式(22)所示:
f(x) = omega^T varphi(x) + b quad (22)
式中:varphi(x) 為x_i in X in R^n 映射到高維空間中的線性可分的非線性高維映射;omega 為權值向量;b為偏置值向量。構造結構風險函數如式(23)所示:
R = frac{1}{2}\omega
^2 + frac{1}{2} c R_{ ext{emp}} quad (23)
式中:$\omega
為控制模型的復雜程度;c為正則化參數;R_{ ext{emp}}$ 為經驗風險。
在支持向量機(SVM)模型建模過程中R_{ ext{emp}} = sum_{i=1}^L e_i^2,則最小化結構風險的優化問題可表示為式(24)和式(25):
min R = frac{1}{2}omega^T omega + r sum_{i=1}^L e_i^2 quad (24)
ext{s.t. } y_i = omega_i varphi(x_i) + b + e_i quad (25)
式中:e為預測誤差值;r為懲罰因子。SSA-LSSVM將上述公式轉化為式(26)和式(27),提高求解速度:
min R = frac{1}{2}omega^T omega + frac{1}{2} c sum_{i=1}^L zeta_i^2 quad (26)
ext{s.t. } y_i = omega_i varphi(x_i) + b + zeta_i quad (27)
式中:zeta_i 為誤差松弛變量,i=1,2,dots,L。
運用Lagrange乘子和對偶變換方法對規劃優化問題進行變換,整理得到下述方程組,如式(28)所示:
�egin{cases} omega_i - lambda_i varphi(x_i) = 0 \ sum_{i=1}^L lambda_i = 0 \ lambda_i = c zeta_i \ omega_i varphi(x_i) + b + zeta_i - y_i = 0 end{cases} quad (28)
式中:lambda_i 為規劃問題的對偶變量。構造如下滿足Mercer定理的核函數:
K(x_i, x_j) = varphi(x_i) varphi(x_j) quad (29)
則優化問題可表示為式(30):
�egin{bmatrix} 0 & I_v^T \ I_v & Omega + c^{-1} I end{bmatrix} �egin{bmatrix} b \ lambda end{bmatrix} = �egin{bmatrix} 0 \ y end{bmatrix} quad (30)
式中:I_v = [1,1,dots,1]^T,共計i個元素,Omega_{ij} = k(x_i, x_j),i, j=1,2,dots,L。
3.2 評價指標
均方根誤差(RMSE)和平均絕對誤差(MAE)[13]用于評估預測模型的預測性能。定義式(31)和式(32)所示:
R_{ ext{MSE}} = sqrt{sum_{t=0}^T frac{(y_t^{ ext{true}} - y_t^{ ext{forecast}})^2}{T}} quad (31)
M_{ ext{AE}} = frac{sum_{t=0}^T y_t^{ ext{true}} - y_t^{ ext{forecast}}
}{T} quad (32)
式中:t為一次勘探時長;T為總時長;y_t^{ ext{forecast}} 和 y_t^{ ext{true}} 分別為時間步t的預測值和實際值。
4 深度強化學習算法
4.1 算法簡介
本文選擇深度強化學習算法中的深度確定性策略梯度算法進行計算和建模。深度確定性策略梯度算法綜合考慮了確定性策略梯度算法[14]中的策略網絡和深度Q網絡中的經驗回放以及評估網絡和目標網絡分離的技巧,在目標進行連續動作的環境中效果顯著。
深度確定性策略梯度算法的步驟如下:
輸入:Actor評估網絡,參數為 heta;Critic評估網絡,參數為varpi;Actor目標網絡,參數為 heta';Critic目標網絡,參數為varpi';衰減因子gamma;最大迭代次數T;批量梯度下降的樣本數m;目標網絡參數更新步數C;軟更新權重系數 au。
輸出:最優的Actor評估網絡參數 heta,最優的Critic評估網絡參數varpi。
隨機初始化 heta、varpi,令 heta' = heta、varpi' = varpi,并清空經驗回放集合D。從1到T(訓練總回合)進行迭代。
(1) 初始化最初狀態s;
(2) Actor評估網絡基于狀態s得到動作a = pi_ heta(s) + N;
(3) 執行動作a,得到新的狀態s',獎勵r,判斷是否為終止狀態done;
(4) 將{s, a, r, s', ext{done}}保存在經驗回放集合D中;
(5) 在經驗回放集合D中平均地選出m個樣本{s, a, r, s', ext{done}}, i=1,2,dots,m,Actor目標網絡根據s'輸出a' = pi_{ heta'}(s') + N,Critic評估網絡根據s, a輸出當前Q值Q(s, a, varpi),Critic目標網絡根據s', a'輸出Q'(s', a', varpi'),計算目標Q值y_i:
y_i = �egin{cases} r_i & ext{is_end}=1 \ r_i + gamma Q'(s_i', a_i', omega') & ext{is_end}=0 end{cases}
(6) 以frac{1}{m}sum_{i=1}^m (y_i - Q(s_i, a_i, omega))^2作為均方差損失函數,用神經網絡的梯度反向傳播來替換Critic評估網絡的參數varpi;
(7) 以J( heta) = -frac{1}{m}sum_{i=1}^m Q(s_i, a_i, omega)表示作為損失函數,用神經網絡的反向傳播來替換Actor評估網絡的參數 heta;
(8) 若T \% C = 1,就用 heta' leftarrow au heta + (1- au) heta'、omega' leftarrow au omega + (1- au)omega'替換Critic目標網絡和Actor目標網絡的參數varpi'和 heta'。
(9) 如果s'顯示為終止狀態,那么這一輪的迭代到此結束,否則讓s = s',并且重新回到步驟(2),繼續迭代。
4.2 算法應用
首先,設置模型的參數。對于每個小時,儲能系統運營商接收一小時前的電價和負荷需求,并對這些值進行預處理。更新輸入向量和預處理數據后,運用LSSVM模型預測接下來幾個小時的價格和負載需求。根據模型預測的數據,得到每小時的最優儲能系統運行功率。設定刺激因子varphi、負荷狀態相關因子(S_{ ext{OC_init}}, S_{ ext{OC_min}}, S_{ ext{OC_max}})和儲能系統設計因子(P^{ ext{dis, min}}, P^{ ext{cha, min}}, C^{ ext{ESS}}, eta^{ ext{dis}}, eta^{ ext{cha}})的模型參數。在每個片段開始之前,初始化Q表和初始狀態。初始狀態s_0由預測值中初始時間段的電價與初始的負荷狀態組成。儲能系統功率的確定策略遵循勘探比貪婪策略,包括勘探和開采,如式(33)所示:
a_t = �egin{cases} ext{random } a_t in A_t & varepsilon > �eta \ operatorname{argmax}_{a_t in A_t} Q(s_t, a_t) & varepsilon leqslant �eta end{cases}
varepsilon = �egin{cases} varepsilon - varepsilon^{ ext{limit}} - varepsilon^{ ext{min}} & varepsilon > varepsilon^{ ext{min}} \ varepsilon^{ ext{min}} & varepsilon leqslant varepsilon^{ ext{min}} end{cases} quad (33)
式中:�eta in [0,1] 為隨機確定的常數;varepsilon 為勘探比。
如果varepsilon大于�eta,則儲能系統運營商執行隨機行為的勘探;如果varepsilon小于�eta,則儲能系統運營商執行開采,其行為對應于當前學習狀態下Q函數的最大值。在訓練的早期階段,需要較高的探索率,通過隨機行為盡可能多地更新Q函數。隨著訓練的進行,需要降低勘探率來開發計算值的模型。公式(34)顯示了隨著章節的迭代,探索比率是如何變化的:
varepsilon = �egin{cases} varepsilon - frac{varepsilon^{ ext{init}} - varepsilon^{ ext{min}}}{M} & varepsilon > varepsilon^{ ext{min}} \ varepsilon^{ ext{min}} & varepsilon leqslant varepsilon^{ ext{min}} end{cases} quad (34)
式中:varepsilon^{ ext{init}} 為初始勘探比;varepsilon^{ ext{min}} 為最小勘探比;M為勘探步長。
當varepsilon值大于varepsilon^{ ext{min}}時,varepsilon值隨迭代次數的增加而減小。由于優化得到的結果可能是局部極大值而不是全局極大值,因此設置了最小勘探比varepsilon^{ ext{min}}。
基于勘探比貪婪策略選擇儲能系統運行功率后,運營商立即從電力市場(環境)獲得獎勵r_{t+1},并觀察下一個狀態s_{t+1}。然后更新Q函數,使用狀態動作轉換(s_t, a_t, r_{t+1}, s_{t+1})。這個過程不斷重復,直到達到最后一個時間步驟的狀態s_{t+1}為止。整個時間步長迭代持續到一個片段,并且這個迭代被重復,直到達到片段的數量N。儲能系統運營商僅將當前小時對應的時間步長t_0的動作作為最優功率。算法繼續到下一個小時,重復上述過程直到最后一個小時。
5 仿真和結果
5.1 測試場景
以來自美國賓夕法尼亞-新澤西-馬里蘭(PJM)電力市場的電價和負荷需求的歷史數據進行測試。其中,以每小時PJM-RTO節點數據作為電價,以地區每小時耗電量數據作為負荷需求。采用表1中總結的參數進行儲能系統建模。
表1 儲能系統模型參數
參數 值 說明
ESS容量C^{ ext{ESS}}/MWh 95 自給時間滿足3小時
P^{ ext{cha, max}}/MW 0.25 C^{ ext{ESS}}
P^{ ext{dis, max}}/MW E^{ ext{load,min}} 用戶負荷需求
ESS充電效率eta^{ ext{cha}} 0.95 磷酸鐵鋰電池
ESS放電效率eta^{ ext{dis}} 0.95 磷酸鐵鋰電池
SOC最小值S_{ ext{OC_min}} 0.2 磷酸鐵鋰電池
SOC最大值S_{ ext{OC_max}} 0.8 磷酸鐵鋰電池
SOC初始狀態S_{ ext{OC_init}} 0.2
測試選定的地區為EASTON[15],該地區位于美國伊利諾伊州梅森郡的一個城鎮,占地62公頃,有居民373人,城鎮內部無自主發電設備。儲能的容量被設定為:以在缺乏電網供電的情況下,為地區提供3h的電力。結合相關數據,儲能系統的容量設定為95 MWh。儲能類型是鋰離子電池,與鋰離子電池耐久性相關的每一個值,如P^{ ext{dis, max}}, P^{ ext{cha, max}}、S_{ ext{OC_min}}和S_{ ext{OC_max}},都是根據鋰離子電池界推薦的通用做法來選擇的。將P^{ ext{dis, max}}設為預測負荷需求中的最小值,以避免供電量超過機組負荷需求。在這個時候,P^{ ext{dis, max}}被限制為不超過1.0C-rate,考慮到耐久性,功率之間的間隔設置為1.0 MW。eta^{ ext{cha}}和eta^{ ext{dis}}是參照傳統鋰離子電池的往返效率來確定的。將SOC的初始狀態設置為0.2,以分析白天進行充電和放電的情況。非高峰/中高峰/高峰時段的激勵因子varphi_t列于表2,根據電網和用戶的特性、儲能系統類型和設計條件,上述參數的值可能有所不同。
表2 不同時期的激勵因素
周期 時間 激勵因子
非高峰 00:00-06:00, 22:00-23:00 0.4
中高峰 07:00-16:00 0.2
高峰 17:00-21:00 0.1
5.2 優化結果
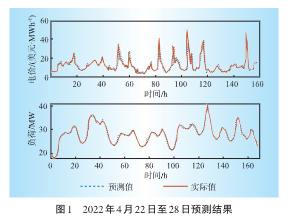
通過最小二乘支持向量機,對PJM電力市場2022年4月22日至2022年4月28日的數據進行預測。將預測的電價和負荷需求與實際值進行比較,結果如圖1所示。使用均方根誤差和平均絕對誤差兩個指標對預測準確性的進行定量評估,對比結果如表3所示。本文的LSSVM模型顯示出較低的平均絕對誤差值,證明了模型設置和訓練的合理有效性。通過對比誤差值可得出結論:LSSVM模型預測負荷數據的性能優于電價的預測性能。
圖1 2022年4月22-28日的預測結果
(原文圖示:展示電價和負荷的預測值與實際值對比曲線)
表3 LSSVM模型預測結果定量評價
均方根誤差 平均絕對誤差
電價預測模型 0.2129 0.1368
負荷預測模型 0.0628 0.0475
表4總結了用于Q學習的超參數,這些超參數是根據RL算法的常見應用選擇的。
表4 強化學習的超參數
超參數 值
貼現因子gamma 0.99
學習率alpha 0.5
初始探索率varepsilon^{ ext{init}} 1.0
最小探索率varepsilon^{ ext{min}} 0.001
勘探步驟M 250000
片段N 300000
為了確認學習過程是否通過應用此算法得到了良好的執行,調查了片段獎勵如圖2所示。片段獎勵是EO的一天收入。圖2(a)顯示了在應用獎勵刺激之前的學習過程,圖2(b)顯示了在4月22日應用獎勵刺激之后的學習過程。如圖2所示,在學習開始時,代理探索并顯示了一個較低的事件獎勵值,隨著學習的進展,此事件獎勵的值增加并最終收斂。實施刺激后,收斂值大于實施刺激前的值,這意味著在實施刺激后進行學習以獲得更多利潤。
圖2 訓練期間片段獎勵的收斂性
(原文圖示:展示有無激勵下的獎勵收斂曲線)
在最初的學習階段,當一天中的許多時間點超過SOC限制時,會出現事件獎勵明顯較小的情況。當幕迭代超過勘探步驟M時,varepsilon值即勘探比率收斂到varepsilon^{ ext{min}}。然后進行額外的50000次開采迭代,以獲得最終收斂值,如圖2所示。即使在250000次開采之后,有時,由于勘探是以varepsilon^{ ext{min}}的最小勘探比率進行的,因此,開采的回報也低于收斂值。在整個學習過程之后,得出了ESS的最優輸出功率。
為了確認應用該算法學習過程是否完成良好,本文對儲能系統的充放電量進行了調查,如圖3所示。圖3顯示了4月22日應用獎勵激勵前后的充放電量對比情況。結果顯示,在學習開始時,運營商勘探并顯示了一個較低的片段獎勵值(片段獎勵即為一段時間內的即時獎勵集合,案例中對應的即為儲能系統運營商一天24h內的即時獎勵之和),隨著學習的進展,該片段獎勵的價值增加并最終趨同。在應用激勵后,儲能充放電量大于應用激勵前的值,這意味著學習是為了在應用激勵后獲得更多的利潤。
圖3 激勵前后儲能系統充放電量對比
(原文圖示:展示有無激勵下的充放電功率曲線)
在施加激勵的情況下,在非峰段充電相對較多,在峰段放電較多。這是由于激勵因子從非高峰時期增加到高峰時期,儲能系統運營商獲得更直接的獎勵r_{t+1}而得到的結果。高電價通常意味著整個電網處于高負荷需求中。因此,從整個電網的角度來看,所提出的激勵整合套利策略有效地將電網的峰值電力負荷分配到較低的峰值。
圖4為2022年4月22日電網運營商峰時供電對比結果圖,電網運營商日間提供的總電量幾乎相同,然而,以降低峰值功率為重點,當采用基本的儲能盈利策略時,約節省了17.5%。當施加激勵策略時,與原本相比節約了30.3%的電量。
圖4 運營商峰時供電對比結果
(原文圖示:展示有無激勵下的電網供電曲線)
相比于未加激勵的情況,儲能系統參與市場交易的意愿大大增加,政府能夠更多地將用電高峰期轉移到非用電高峰期。綜合考慮這些結果,因此可以得出結論:激勵整合盈利對儲能系統運營商的利潤和電網可靠性是一個雙贏的策略。
6 結束語
本文提出了一種考慮激勵策略的儲能系統盈利模式,并進行了案例驗證。結果顯示,該激勵策略對儲能系統運營商和電網運營商來說都是有利的。它也可以通過峰谷套利以及激勵機制,給儲能系統運營商帶來更高利潤;降低電網峰時供電壓力。但是并未考慮政府對儲能系統的補貼政策以及新能源裝機補貼等問題,所以還需要進一步的研究和完善。
參考文獻
[1] 葛興凱. 儲能系統盈利模式及應用實例分析[J]. 新型工業化, 2021, 11(8): 168-169, 171.
[2] 劉堅. 適應可再生能源消納的儲能技術經濟性分析[J]. 儲能科學與技術, 2022, 11(1): 397-404.
[3] 黨曉圓, 賴偉. 基于能量套利的儲能價值評估模型[J]. 現代電子技術, 2021, 44(23): 180-186.
[4] ZAKERI B, SYRI S. Electrical energy storage systems: A comparative life cycle cost analysis[J]. Renewable & Sustainable Energy Reviews, 2015, 56: 549-596.
[5] FU Q, MONTOYA L F, SOLANKI A, et al. Microgrid generation capacity design with renewables and energy storage addressing power quality and surety[J]. IEEE Transactions on Smart Grid, 2012, 3(4): 2019-2027.
[6] KRISHNAMURTHY D, UCKUN C, ZHOU Z, et al. Energy storage arbitrage under day-ahead and real-time price uncertainty[J]. IEEE Transaction on Power System, 2018, 33: 84-93.
[7] WANG H, ZHANG B S. Energy storage arbitrage in real-time markets via reinforcement learning[C]. in IEEE Power & Energy Society General Meeting, New York, 2018.
[8] ZHAO H, WU Q, HU S, et al. Review of energy storage system for wind power integration support[J]. Applied Energy, 2015, 137: 545-553.
[9] FLEGKAS S, BIRKELBACH F, WINTER F, et al. Profitability analysis and capital cost estimation of a thermochemical energy storage system utilizing fluidized bed reactors and the reaction system MgO/Mg(OH)2[J]. Energies, 2019, 12(24): 4788.
[10] SUN W Q, ZHANG J, ZENG P L, et al. Energy storage configuration and day-ahead pricing strategy for electricity retailers considering demand response profit[J]. International Journal of Electrical Power & Energy Systems, 2022, 136: 142-615.
[11] 虞啟輝, 田利, 李曉飛, 等. 考慮風能不確定性的壓縮空氣儲能容量配置及經濟性評估[J]. 儲能科學與技術, 2021, 10(5): 1614-1623.
[12] 鄭偉立, 何茹玥, 李垣彤, 等. 基于“套利”視角的儲能產業商業邏輯研究[J]. 發展研究, 2021, 38(4): 18-24.
[13] 周磊, 吳輝, 嵇文路, 等. 微電網脆弱性預評估方法[J]. 電力需求側管理, 2018, 20(1): 20-24.
[14] 魏小曼, 余昆, 陳星鶯, 等. 基于Affinity propagation和K-means算法的電力大用戶細分方法分析[J]. 電力需求側管理, 2018, 20(1): 15-19, 35.
[15] 王一, 馬子明, 譚躍凱, 等. 廣東日前電力市場方案設計與市場仿真[J]. 電力需求側管理, 2018, 20(1): 10-14.




